파이썬 구현체 CPython의 GIL (Global Interpreter Lock)은 파이썬 바이트코드를 실행할 때, 여러 쓰레드 중 하나의 쓰레드만이 파이썬 객체에 접근할 수 있게 하는 mutex (mutual exclusive) 로서 하나의 프로세스의 공유 리소스를 하나의 쓰레드만이 점유하게 하는 장치입니다. 따라서 파일 읽기/쓰기, 네트워크 통신 등과 같은 I/O 작업이 아닌 행렬연산, 이미지처리 등 CPU를 많이 사용하는 작업에 대해서는 파이썬의 멀티쓰레드로는 성능향상을 기대할 수 없는데요, 다음 코드를 보면 다중쓰레드가 락 (mutex)의 획득, 해제에 따른 오버헤드로 인해 실행 시간이 더 길게됩니다.
# single_threaded.py
import time
from threading import Thread
COUNT = 50000000
def countdown(n):
while n>0:
n -= 1
start = time.time()
countdown(COUNT)
end = time.time()
print('Time taken in seconds -', end - start)
# multi_threaded.py
t1 = Thread(target=countdown, args=(COUNT//2,))
t2 = Thread(target=countdown, args=(COUNT//2,))
start = time.time()
t1.start()
t2.start()
t1.join()
t2.join()
end = time.time()
print('Time taken in seconds -', end - start)
$ python single_threaded.py
Time taken in seconds - 6.20024037361145
$ python multi_threaded.py
Time taken in seconds - 6.924342632293701운영체제가 각 프로세스 별로 별도의 메모리 공간을 할당하는 멀티프로세싱과 달리 멀티쓰레드는 하나의 프로세스에서 자원을 공유하므로 전역변수에 대해 두 개 이상의 쓰레드가 동시에 접근할 때 간단한 코드조차도 제대로 돌아가지 않는 것을 지난 포스트에서 확인한 바 있습니다. 그렇다면 파이썬에서는 왜 GIL을 멀티쓰레딩의 성능 이득이 없음에도 계속 사용하는 이유는 무엇일까요?
답은 파이썬의 메모리관리에 있습니다. 파이썬에서의 모든 객체는 해당 객체가 얼마나 참조되었는지 reference count 변수를 지니고 있고 이 count가 0이 되면 메모리에서 해제됩니다. 다음과 같이 sys 모듈의 getrefcount 함수로 알 수 있고 빈 리스트 ([])는 a, b, getrefcount 함수 argument 총 3번 참조되었기에 reference count가 3이 되게 됩니다.
>>> import sys
>>> a = []
>>> b = a
>>> sys.getrefcount(a)
3또한, 지난 포스트에서 파이썬 객체의 C 구조체인 PyObject는 reference 개수와 그 타입을 가지도록 선언되어 있습니다.
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;이러한 상황에서 두 개 이상의 쓰레드가 값에 동시에 접근하는 race condition이 발생한다면 메모리 leak이나 객체의 참조가 살아있음에도 메모리 상에서 해제되버리는 버그가 발생할 수 있습니다. 그렇다면 각 객체 별로 mutex를 걸어버리는 방법이 있겠으나 수많은 락의 획득, 해제 오버헤드에 의한 성능감소와 더불어 데드락 (교착상태)가 발생할 수 있는 여지가 있습니다.

따라서 CPython은 모든 객체의 reference count를 보호하는 대신 파이썬 인터프리터 자체를 잠궈버리는 방식을 취합니다. 단일 락이므로 데드락이 발생할 우려가 없고 성능감소를 일으키는 오버헤드가 거의 없는 바업이죠. 따라서 객체의 reference counter를 추적하는 파이썬의 메모리관리 방식으로 인해 파이썬은 태생적으로 다중쓰레드를 이용한 병렬처리를 막아버리게 된 것이죠. 일반적으로 GIL은 단일쓰레드 프로그램에서 최적의 성능을 보장하는 방법으로 Ruby에서도 사용되는 방법입니다.
다른 방법은 없었을까요? 파이썬이 태동한 1990년대 초반에는 쓰레드라는 개념이 존재하지 않는 시절로 파이썬은 개발속도를 빠르게 하기 위한 쉽고 간결함을 위해 개발된 언어입니다. 수많은 C 라이브러리의 extension이 개발되었는데, 쓰레드의 개념이 태동하고 멀티쓰레드가 대두하면서 C 라이브러리 extension의 변화를 막기위한 가장 현실적인 방법이 쉬우면서도 하나의 락만 사용하여 단일쓰레드에서 성능을 어느정도 보장하는 GIL이었습니다. 따라서 기존의 C 라이브러리들을 바꾸지 않아도 되었던 것이죠.
물론 GIL을 없애려는 많은 개발자들의 시도가 있긴 했습니다. 하지만 GIL에 깊게 의존하는 C 라이브러리들을 완벽히 치환하는 것이 어려울 뿐만 아니라 더 어렵고 단일쓰레드에서의 성능감소를 막을 수가 없었죠. 파이썬의 창시자이자 자비로운 독재자 (BDFL) 귀도 반 로썸은 "단일쓰레드에서 성능을 저하시키지 않고 GIL의 문제를 해결할 수 있다면 그 개선안을 받아들이겠다"고 말했지만 이를 만족하는 개선안은 아직 나오지 않은 상황입니다.
그래도 파이썬 3이 도입되면서 GIL 자체에 대한 성능개선이 이뤄졌습니다. 기존에 CPU-bound 쓰레드와 I/O-bound 쓰레드가 섞여있는 멀티쓰레드 상황에서 CPU-bound 쓰레드가 리소스를 지속적으로 점유하는 현상이 있었는데, Figure 1과 같이 Thread 1이 UDP 패킷을 보내는 I/O-bound, Thread 2가 CPU-bound 일때 Thread 2만이 거의 모든 순간에 리소스를 점유하는 것을 볼 수 있습니다.
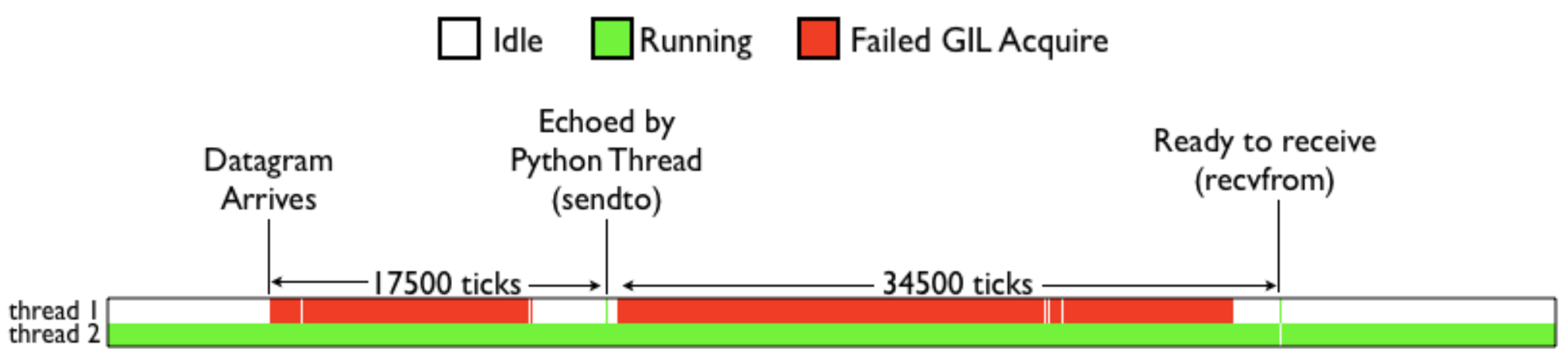
이 문제는 CPU-bound 쓰레드가 대부분 시간동안 GIL을 해제하면서 다른 쓰레드가 GIL을 얻기 전에 GIL을 재획득하는 현상 때문인데요, 이는 각 쓰레드 별로 GIL 획득 횟수를 추적하고 현재 쓰레드가 GIL을 재획득하는 것을 막는 방법으로 2009년 파이썬 3.2 버젼에서 수정되었습니다.
파이썬에서 병렬화를 이용한 성능향상을 추구하려면 멀티프로세싱을 하는 것이 가장 일반적으로 파이썬에는 multiprocessing, concurrent.futures 와 같은 병렬 라이브러리를 제공하고 있습니다. 또한, 파이썬 인터프리터 구현체는 CPython 이외에도 Jython, IronPython, PyPy 등이 존재하는데 GIL은 CPython에만 존재합니다.
from multiprocessing import Pool
import time
COUNT = 50000000
def countdown(n):
while n>0:
n -= 1
if __name__ == '__main__':
pool = Pool(processes=2)
start = time.time()
r1 = pool.apply_async(countdown, [COUNT//2])
r2 = pool.apply_async(countdown, [COUNT//2])
pool.close()
pool.join()
end = time.time()
print('Time taken in seconds -', end - start)
$ python multiprocess.py
Time taken in seconds - 4.060242414474487
참조
'Computer > Python' 카테고리의 다른 글
| Shallow copy vs Deep copy (0) | 2021.08.01 |
|---|---|
| List Subtraction (0) | 2021.07.26 |
| Decorator 에서 함수 디폴트 인자 파악 방법 (0) | 2021.07.20 |
| namedtuple 인스턴스 확인 (0) | 2021.07.19 |
| 파이썬의 memory management (3) | 2021.07.14 |
