merge
Pandas의 merge 함수는 두 개의 데이터프레임 (DataFrame)을 합치는 함수입니다. 먼저 다음과 같은 두 개의 데이터프레임을 생성하겠습니다.
df1 = pd.DataFrame({'key': list('bbacaab'), 'data1': range(7)})
df2 = pd.DataFrame({'key': list('aabde'), 'data2': range(13,18)})
두 개의 데이터프레임은 'key' 라는 공통적인 열을 가지고 있습니다. Pandas의 merge 함수를 실행하면 자동으로 이름이 같은 공통된 열을 찾습니다. 디폴트로 실행할 경우 how='inner' 방식으로 동작하는데 이 방식은 두 데이터프레임의 공통된 열이 같은 값을 가지는 것에 대한 열에 대해서만 합치게 됩니다. 즉, df2의 key 열에서 d와 e는 df1에 존재하지 않으므로 합쳐질 때 삭제됩니다.

또한 공통적인 값을 가진 줄에 대해서는 모든 경우를 생성합니다. 즉, df1의 key가 b인 경우 0,1,6이 존재하고 df2의 key가 b인 경우는 15이므로 합쳐질때에는 [0,15],[1,15],[6,15] 의 모든 경우로 합쳐지게 됩니다. 마찬가지로 df1의 key가 a인 경우 2,4,5이고 df2의 key가 a인 경우 13,14이므로 합쳐질 경우 [2,13],[2,14],[4,13],[4,14],[5,13],[5,14] 의 경우로 합쳐지게 됩니다.
how 파라미터에 'outer' 인자를 주게 되면 한 쪽 데이터프레임에만 있는 행들도 추가합니다. 즉, df2의 d,e 행도 합쳐진 데이터프레임에 포함됩니다. 이때, df1에는 d,e에 해당하는 값이 없으니 NaN으로 되어서 합쳐지게 됩니다.
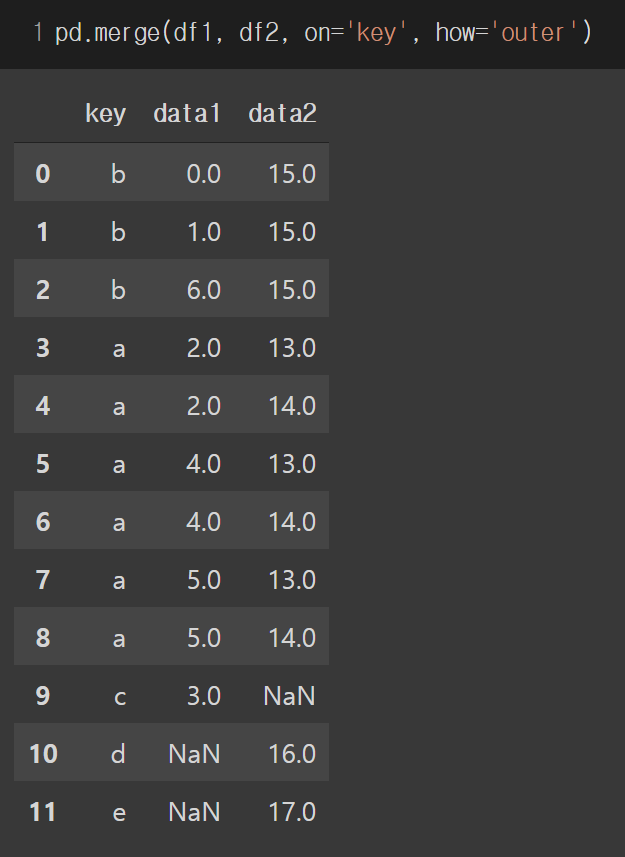
how 에 'left' 인자를 주게 되면 왼쪽에 있는 df1이 고정되고 df2는 동일한 키 값을 가질 때마다 붙게 되며 df2에 해당하는 값이 없으면 NaN으로 붙여집니다.
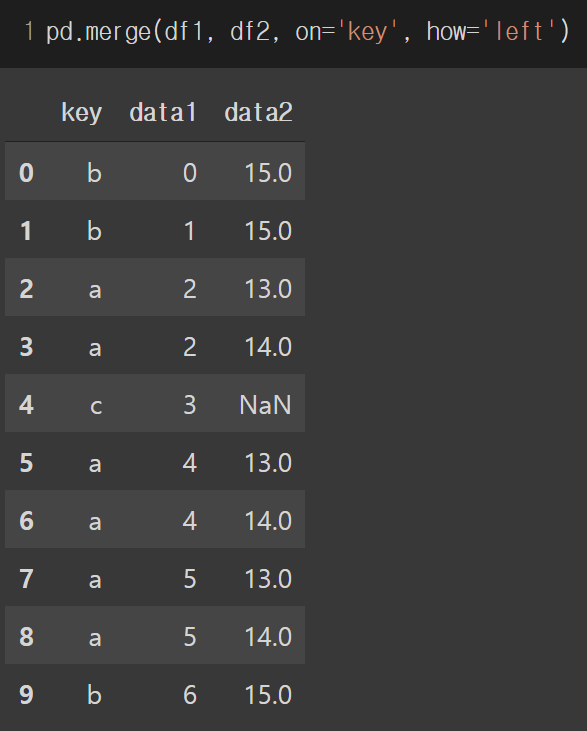
how 에 'right' 인자를 주게 되면 오른쪽에 있는 df2가 고정됩니다.

두 개의 데이터프레임에 공통된 이름의 열이 없어도 merge 함수의 left_on, right_on 파라미터를 통해 합칠 기준이 될 열 이름을 전달할 수 있습니다. 다음과 같은 데이터가 있을 때,
df3 = pd.DataFrame({'lkey': list('bbacaab'), 'data1': range(7)})
df4 = pd.DataFrame({'rkey': list('aabd'), 'data2': range(13,17)})
pd.merge를 그대로 실행할 경우 에러가 발생합니다.

merge 함수를 수행할 때, left_on, right_on 인자를 전달하면 inner 방식으로 합쳐집니다.
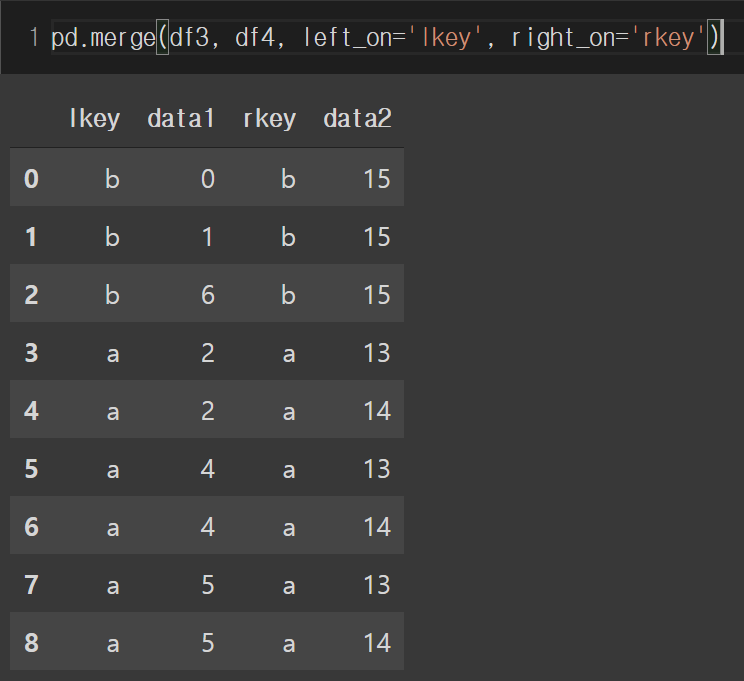
데이터프레임을 합칠 열 이름을 지정하면 나머지는 위에서 언급한 방식대로 동작합니다.

인덱스를 기준으로도 merge 할 수 있습니다. 다음과 같은 데이터가 있을 때,
left = pd.DataFrame({'key': list('abaabc'), 'value': range(6)})
right = pd.DataFrame({'group_val':[3,7]}, index=['a','b'])
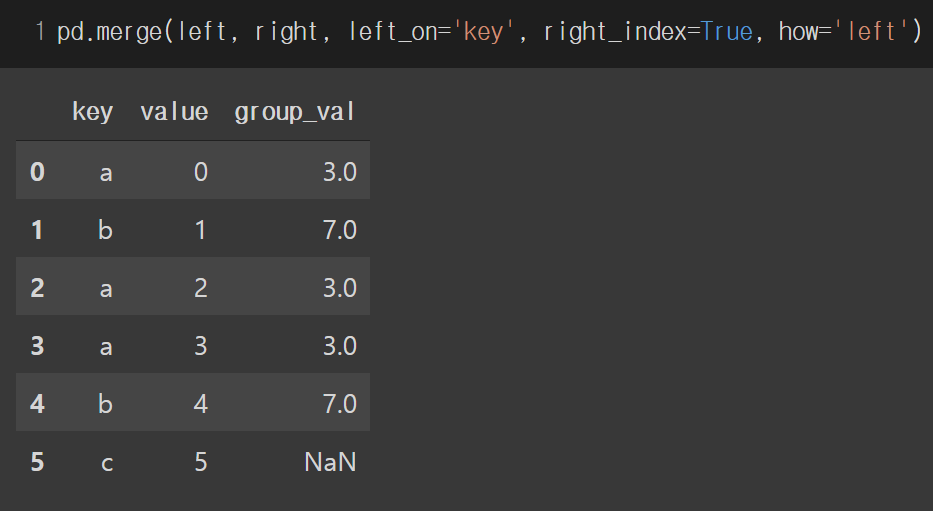
왼쪽 데이터프레임의 특정한 열과 오른쪽 데이터프레임의 인덱스를 기준으로 합치고 싶을 때에는 left_on 에 열 이름을 넣어주고 right_index 를 True로 바꾸어주면 됩니다. 반대의 경우에는 right_on 에 오른쪽 데이터프레임의 열 이름을 넣어주고 left_index 를 True로 바꾸어주면 됩니다.

how 인자에 'left'를 적용할 경우 위의 경우와 마찬가지로 동작합니다.
두 개의 데이터프레임 모두 인덱스를 기준으로 합칠 수 있습니다. 다음 데이터가 있을 때,
left = pd.DataFrame([[1,2],[3,4],[5,6]], index=['a', 'c', 'e'], columns=['Seoul', 'Incheon'])
right = pd.DataFrame([[7,8],[9,10],[11,12],[13,14]], index=['b','c','d','e'], columns=['Daegu', 'Ulsan'])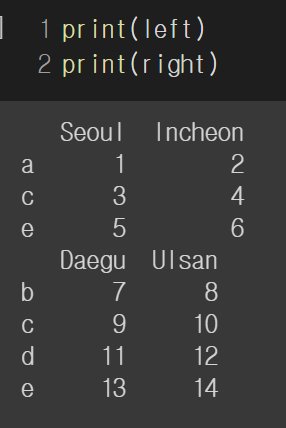
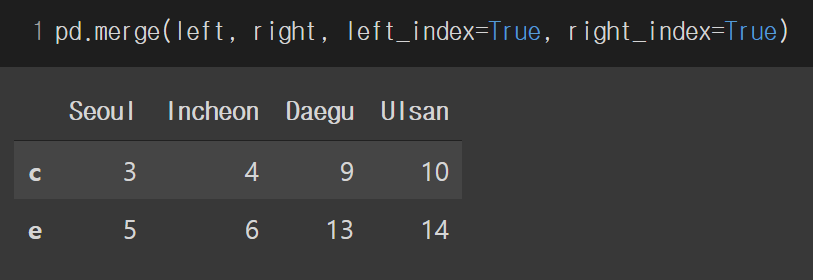
left_index 와 right_index 를 모두 True로 설정하면 how='inner' 방식으로 합쳐집니다.
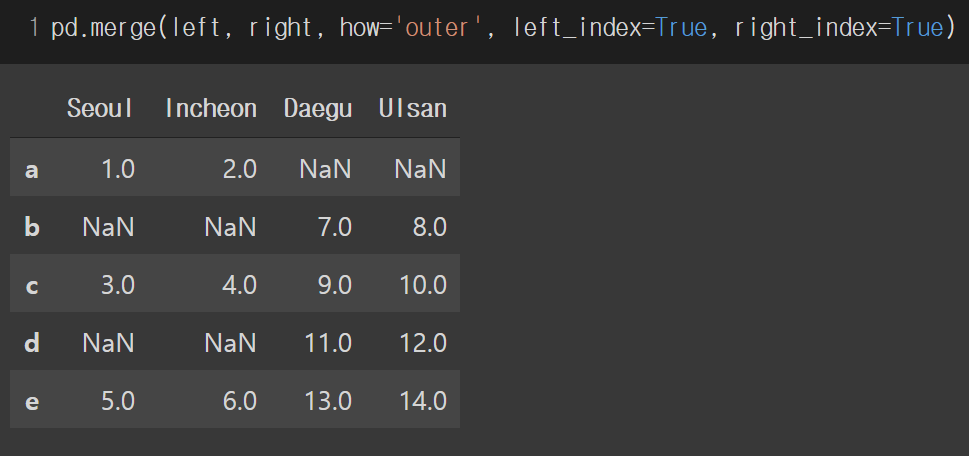
how='outer'의 경우에도 위와 마찬가지로 동작합니다.
concat
Pandas의 concat 함수는 두 데이터프레임을 행이나 열 방향으로 단순 연결하는 것으로 두 개의 데이터프레임을 리스트화하여 파라미터로 전달합니다. 먼저, series 데이터를 다음과 같이 선언하고
s1 = pd.Series([0,1], index=['a','b'])
s2 = pd.Series([2,3,4], index=['c','d','e'])
s3 = pd.Series([5,6], index=['f','g'])
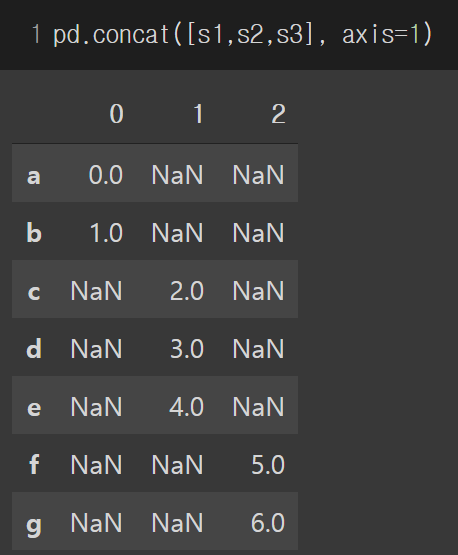
pd.concat()에 [s1,s2,s3]를 전달하면 디폴트 축은 axis=0이므로 행이 연결되는 것을 볼 수 있습니다.

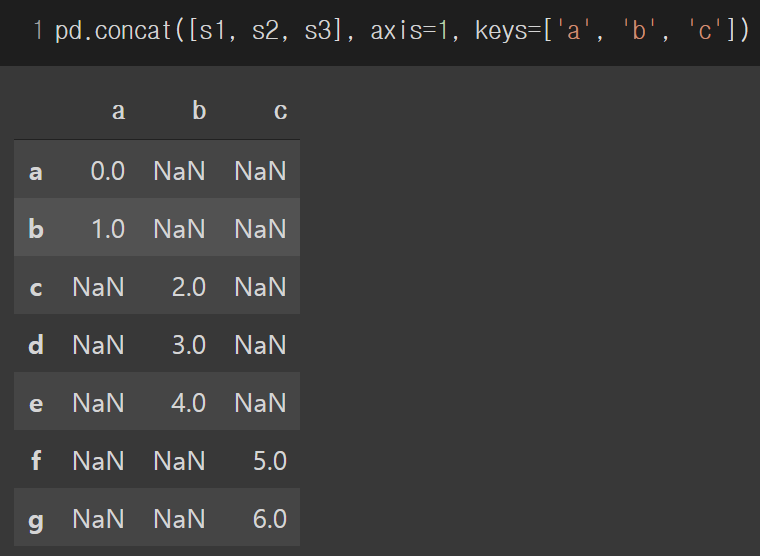
axis=1로 했을 시 열이 합쳐지며 빈 column은 NaN으로 채워집니다.
keys 파라미터에 열 이름을 지정할 수 있습니다.
데이터프레임에도 마찬가지로 동작합니다. 먼저 다음과 같이 데이터프레임을 선언하고,
df1 = pd.DataFrame(np.arange(6).reshape(3,2), index=['a','b','c'], columns=['one','two'])
df2 = pd.DataFrame(np.arange(4).reshape(2,2)+5, index=['a','c'], columns=['two','three'])
axis=1에 대해 합치면 밑의 그림과 같은 합쳐진 데이터프레임이 생성됩니다. 이때, 열 이름이 중복되더라도 중복된 열은 합쳐지지 않고 개별적으로 존재합니다.

행으로 합칠 때 인덱스 이름이 중복되더라도 그대로 연결됩니다.

ignore_index를 True로 지정하면 기존 인덱스를 신경쓰지 않고 붙이면서 새로운 인덱스를 자동으로 생성합니다. 따라서 concat을 이용해 행으로 합칠 때에는 index_index를 True로 설정하는 것이 좋고 열 방향으로 합칠 때에는 중복된 열 이름을 미리 바꾸어 놓는 것이 좋습니다.

참조
'Computer > Pandas' 카테고리의 다른 글
| Onehot 인코딩의 역변환 (inverse transform) (0) | 2021.07.25 |
|---|---|
| Pandas Multiple Columns Label Encoding (1) | 2021.07.14 |
| Pandas 에서 데이터 이상치 찾기 - Z-score, Modified Z-score, IQR (0) | 2021.03.31 |
| Pandas - datetime64 타입 (0) | 2021.03.26 |
| Pandas - get_dummies 함수 (0) | 2021.03.25 |



