Pandas 데이터프레임 형태의 데이터를 머신러닝 알고리즘에 적용하기 위해서는 범주형으로 존재하는 칼럼을 어떻게든 수치화시켜주어야 합니다. Scikit-learn이나 pandas 패키지의 함수를 가지고 쉽게 수행할 수 있으며 대표적인 방법으로는 1) 범주의 개수만큼 열을 새롭게 생성하여 해당하는 범주의 열에 대해서 1, 나머지 열에 대해서는 0을 할당하는 one-hot 인코딩과 (pandas.get_dummies) 2) 0부터 범주 개수 -1 만큼의 수를 각 범주에 할당하는 Label 인코딩이 있습니다.
보통 one-hot 인코딩을 주로 사용하나 추후 Pytorch 같은 딥러닝 프레임워크를 이용할 때에는 정의된 크로스엔트로피 로스의 타겟이 라벨 인코딩 형태로 되어있기 때문에 Label 인코딩을 수행해야하며, scikit-learn.preprocessing 모듈의 LabelEncoder 클래스를 사용하면 됩니다. 이번 포스트에서는 LabelEncoder 클래스를 이용해서 범주형 칼럼이 여러개이고 지정한 칼럼만 라벨 인코딩을 한 번에 수행할 수 있는 구현방법에 대해 알아보도록 하겠습니다.
먼저 LabelEncoder 클래스의 간단한 예를 다음과 같습니다. scikit-learn 패키지에 속한 다른 api와 마찬가지로 1) 클래스 인스턴스를 선언하고 2) fit() 함수를 통해 관련 속성을 계산하고 3) transform() 함수를 통해 데이터 변환을 수행합니다. 물론 2, 3 과정을 fit_transform() 함수를 통해 한 번에 수행할 수 있습니다.
>>> le = preprocessing.LabelEncoder()
>>> le.fit(["paris", "paris", "tokyo", "amsterdam"])
LabelEncoder()
>>> list(le.classes_)
['amsterdam', 'paris', 'tokyo']
>>> le.transform(["tokyo", "tokyo", "paris"])
array([2, 2, 1]...)
>>> list(le.inverse_transform([2, 2, 1]))
['tokyo', 'tokyo', 'paris']하지만 중요한 점은 라벨 인코딩은 하나의 범주형 칼럼에 대해 적용되기 때문에 범주형 칼럼이 여러개이거나 데이터프레임 자료구조는 LabelEncoder 클래스의 fit()/fit_transform() 함수의 인자로 전달할 수 없다는 점입니다. 다음 예와 같이 fit() 함수에 하나의 칼럼만 선택한 1차원 시리즈 구조를 전달할 경우 에러가 발생하지 않지만 2차원인 데이터프레임 구조를 전달할 경우 ValueError가 발생합니다.
import pandas as pd
from sklearn.preprocessing import LabelEncoder
df = pd.DataFrame({
'pets': ['cat', 'dog', 'cat', 'monkey', 'dog', 'dog'],
'owner': ['Champ', 'Ron', 'Brick', 'Champ', 'Veronica', 'Ron'],
'location': ['San_Diego', 'New_York', 'New_York', 'San_Diego', 'San_Diego', 'New_York']
})
LabelEncoder().fit(df['pets'])
LabelEncoder().fit(df)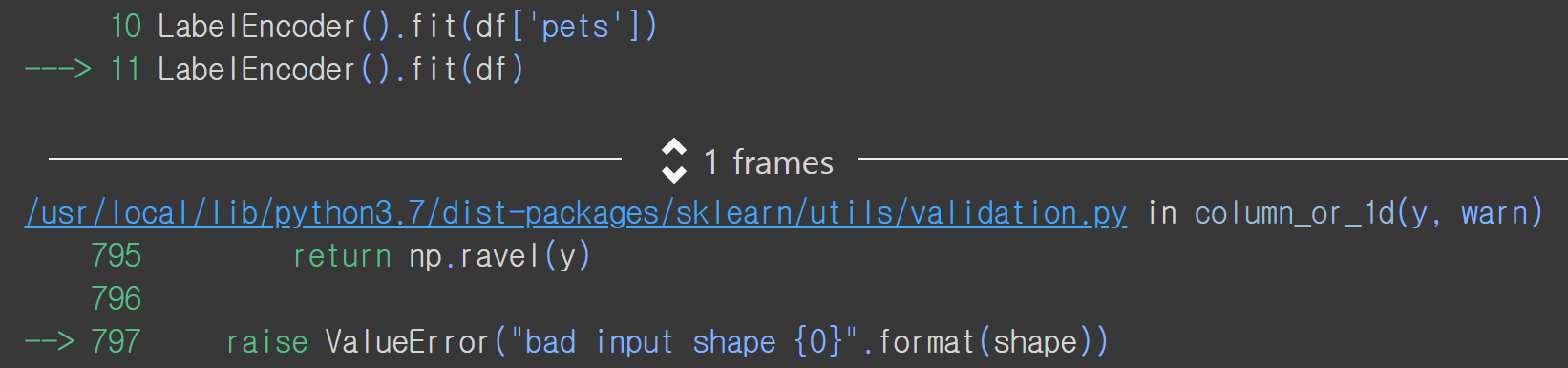
그렇다면 이를 모든 범주형 칼럼에 대해 한 번에 수행할 수 있는 방법은 무엇일까요? 먼저 데이터프레임을 전달했을 때 각 칼럼 별로 LabelEncoder() 클래스 인스턴스가 생성되어 fit_transform() 함수를 수행해야 합니다. 여기서 활용할 수 있는 방법으로는 Pandas의 apply 함수를 이용하는 것입니다. apply 함수의 인자로는 각 열 (axis=0)이나 각 행 (axis=1)에 대해 수행할 함수가 전달되며, 각 열마다 LabelEncoder() 클래스 인스턴스를 생성하고 fit_transform() 함수를 수행하면됩니다. 이때 추후 원래 라벨로 돌리는 inverse_transform() 함수 적용을 위해 각 열 이름별로 LabelEncoder() 클래스 인스턴스를 저장하는 딕셔너리를 정의합니다.
from collections import defaultdict
class MultiColLabelEncoder:
def __init__(self):
self.encoder_dict = defaultdict(LabelEncoder)
def fit_transform(self, X: pd.DataFrame, columns: list):
if not isinstance(columns, list):
columns = [columns]
output = X.copy()
output[columns] = X[columns].apply(lambda x: self.encoder_dict[x.name].fit_transform(x))
return output- X[columns]에 apply 함수를 적용하면 lambda x의 x는 각 칼럼으로 이루어진 시리즈 구조가 되어 x.name으로 칼럼의 이름을 얻을 수 있습니다.
이후에 inverse_transform 함수도 정의합니다. 이때 인자로 주어진 칼럼이 딕셔너리에 등록되어있지 않으면 fit_transform() 함수가 수행되지 않은 것이므로 에러를 발생시킵니다.
def inverse_transform(self, X: pd.DataFrame, columns: list):
if not isinstance(columns, list):
columns = [columns]
if not all(key in self.encoder_dict for key in columns):
raise KeyError(f'At least one of {columns} is not encoded before')
output = X.copy()
try:
output[columns] = X[columns].apply(lambda x: self.encoder_dict[x.name].inverse_transform(x))
except ValueError:
print(f'Need assignment when do "fit_transform" function')
raise
return output위에서 구현한 것을 이용하여 예제에 대해 적용해보겠습니다.
mcle = MultiColLabelEncoder()
transformed_data = mcle.fit_transform(df, columns=['pets', 'owner'])
transformed_data.head()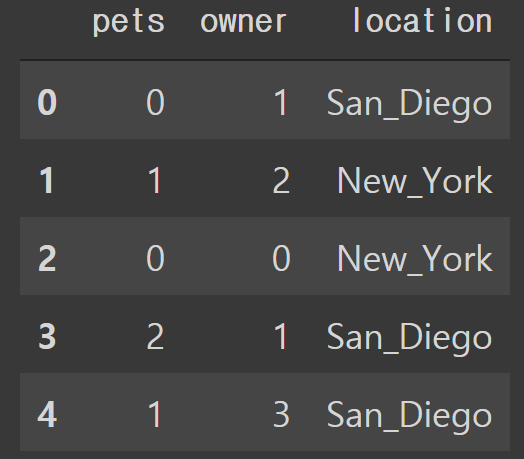
inverse_transform 함수도 잘 수행된 것을 볼 수 있습니다. 지금은 편의상 inverse를 수행할 칼럼을 지정하게 해놨지만 딕셔너리의 키를 이용하여 컬럼을 따로 지정하지 않아도 라벨 인코딩이 수행된 컬럼에 대해서 원래 라벨로 원복시킬 수 있게 구현할 수 있습니다.
mcle = MultiColLabelEncoder()
transformed_data = mcle.fit_transform(df, columns=['pets', 'owner'])
org_data = mcle.inverse_transform(transformed_data, columns=['pets', 'owner'])
org_data.head()
'Computer > Pandas' 카테고리의 다른 글
| Pandas Categorical Data (0) | 2021.08.01 |
|---|---|
| Onehot 인코딩의 역변환 (inverse transform) (0) | 2021.07.25 |
| Pandas DataFrame 합치기 - merge, concat (0) | 2021.03.31 |
| Pandas 에서 데이터 이상치 찾기 - Z-score, Modified Z-score, IQR (0) | 2021.03.31 |
| Pandas - datetime64 타입 (0) | 2021.03.26 |


