분산분석 (ANOVA, ANalysis Of VAriance) 이란 두개 이상의 모집단을 비교할때 사용하는 통계 검정방법으로 t-검정과는 달리 F-분포를 이용한 F-검정의 한 종류입니다. t-검정은 두 집단에 대해서 비교를 하는 것이지만 ANOVA의 경우 두개 이상의 그룹에 대해서도 비교가 가능합니다. ANOVA 수행을 위해서는 1) 데이터가 정규분포를 따르며, 2) 각 모집단의 분산이 동일하며 (등분산), 3) 각각의 모집단에서 샘플이 독립적으로 추출된다는 전제조건이 만족되어야 합니다.
여러 개의 집단 비교시 ANOVA를 사용하는 이유는 t-검정으로 두 집단씩 여러번 비교하게 되면 신뢰도 $1-\alpha$가 독립적으로 여러 번 곱해지므로 신뢰도가 급격하게 감소하게 됩니다. 하지만 분산분석은 F-분포를 이용하여 비교 검정이 단 한번 일어나므로 이러한 현상이 발생하지 않습니다.
분산분석은 종속변수 (dependent variable, 보통 연속적)에 영향을 미치는 요인인 factor의 개수에 따라 one-way ANOVA, two-way ANOVA, n-way ANOVA로 나눌 수 있습니다. 이때 ANOVA는 factor에 따라 두개 이상의 그룹으로 나누어져도 비교 검정을 수행할 수 있습니다.
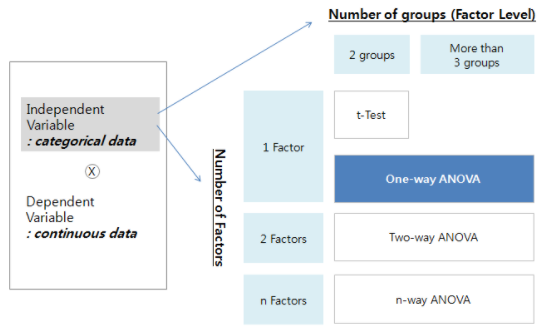
분산분석 시에는 1) 모든 데이터는 정규분포를 따르는 모집단으로부터 추출되고 (정규분포라고 보기 어려운 경우에는 로그 변환을 사용합니다), 2) 모든 데이터는 모집단들로부터 독립적으로 추출되며, 3) 모든 데이터는 평균이 달라도 분산은 동일한 모집단들로부터 추출된다는 가정이 뒷받침 되어야 합니다. 3번의 등분산성 (homoscedasticity) 가정은 큰 분산과 작은 분산이 4:1을 넘지 않으면 분산분석을 사용해도 괜찮으며 분산의 차이가 클 경우 제곱근 변환을 사용하여 분산 차이를 최소화합니다.
One-way ANOVA
One-way ANOVA는 독립변인, 종속변인이 각각 1개일 때 집단 간의 차이를 검정하는 것으로 예를 들어 한/중/일 국가간 학습기술에 따른 성적비교를 수행할 때에는 종속변인은 성적, 독립변인은 학습기술이 됩니다.

ANOVA는 기본적으로 여러 그룹간의 평균의 차이가 통계적으로 유의미한지를 각 그룹 간 분산과 그룹 내 분산을 이용해 검사합니다. 즉, 1) 그룹 평균값의 분산이 클수록, 2) 그룹 내 분산이 작아직수록 그룹간 평균의 차이가 분명해지는 원리에 기반한 것으로 예를 통해 살펴보도록 하겠습니다.
Example
| 요인 | Group 1 | Group 2 | Group 3 |
| 11 | 8 | 5 | |
| 10 | 7 | 4 | |
| 8 | 5 | 2 | |
| 7 | 4 | 1 | |
| 평균 | 9 | 6 | 3 |
위와 같은 데이터가 존재한다고 했을 때 각 그룹 간의 평균의 차이가 있는지를 검사하고 싶습니다. 따라서 귀무가설은 $H_0: \mu_1=\mu_2=\mu3$으로 가정하고 이에 대한 대립가설 $H_1$은 적어도 한 쌍의 모평균을 같지 않다가 됩니다. ANOVA를 위해서 그룹 내 분산과 그룹 간 분산을 비교하고 분산비교를 위해 F 검정통계량을 구합니다. 결론적으로 그룹 간 분산이 그룹 내 분산보다 매우 클 경우 귀무가설을 기각합니다.
$m$을 그룹 수, $n$을 그룹 별 표본 수, $\hat{X}$를 전체 평균으로 한 후 (여기선 6) 그룹 간 분산을 계산하기 위해 먼저 전체 평균과 각 그룹 간 평균의 에러의 제곱의 합을 구하고,
$n\sum_{i=1}^m (\hat{X}_i - \hat{X})^2 = 4*((-3)^2+0^2+3^2)=72$
이를 자유도 $m-1=2$로 나누면 36이 됩니다. (이를 $S_{intergroup}$이라 하겠습니다) 비슷한 방식으로 그룹 내 분산을 계산하기 위해 각 그룹 내 평균과 관측값의 차이의 평균의 합을 구하고
$\sum_{i=1}^m \sum_{k=1}^n (X_{ik}-\hat{X}_i)^2 = 30$
이를 자유도 $n(m-1)=9$로 나누면 3.33이 됩니다. (이를 $S_{intragroup}$이라 하겠습니다) 최종적으로 분산비 F 검정통계량은 '그룹 간 분산/그룹 내 분산'으로 정의되어 10.8의 값을 가지게 되며, 검정통계량은 자유도가 $(m-1, m(n-1))$인 F-분포를 따르게 됩니다. 미리 계산해놓은 F-분포표를 이용하여 p-value를 구할 수 있고 이를 통해 귀무가설 기각 여부를 판단할 수 있습니다. 이 경우에는 p-value가 0.00405 이므로 유의수준 0.05보다 매우 낮아 귀무가설을 기각할 수 있습니다.
그렇다면 그룹 간 분산/그룹 내 분산이 F 검정통계량이 되는 이뉴는 무엇일까요? 각 그룹의 모분산이 $\sigma^2$로 같다고 할때, 그룹 간 분산의 분포는 다음과 같이 자유도가 '그룹수-1'인 카이제곱 분포를 따르고
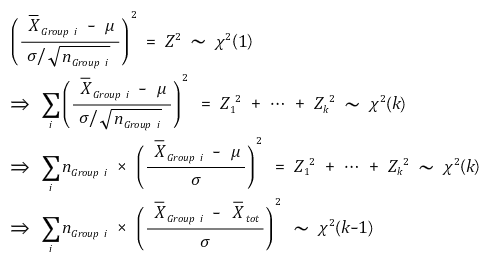
그룹 내 분산의 분포는 다음과 같이 자유도가 '그룹수*(그룹당 표본 - 1)'인 카이제곱 분포를 따릅니다. 위와 마찬가지로 모평균이 표본평균으로 대체되었을때 자유도가 1 감소합니다. (카이제곱 분포의 특성 4에 의해서 유도됩니다)

따라서 위에서 구한 $S_{intergroup}$과 $S_{intragroup}$은 각각 $\frac{\chi^2(그룹수 -1)}{(그룹수 -1)}$, $\frac{\chi^2 (그룹수*(그룹당 표본-1))}{그룹수*(그룹당 표본 - 1)}$의 분포를 따르게 되어 F-분포 정의에 따라 F 검정통계량으로 사용할 수 있습니다. ($\sigma$는 등분산성을 가정하므로 제거됩니다)
ANOVA를 통해 귀무가설이 기각될 경우에는 최소한 한 쌍의 그룹 간에 평균이 다르다는 결론을 얻을 수 있지만 어느 그룹이 다른지는 알 수 없습니다. 이를 파악하기 위해서는 최소 유의적 차이 검정 (LSD, Least Significant Difference)등과 같은 추가적인 사후 검정 (posterior test)를 수행하여야 합니다.
파이썬에서는 scipy.stats 모듈의 f_oneway 함수를 통해 검정통계량과 p-value를 얻을 수 있습니다.
Two-way ANOVA
Two-way ANOVA는 one-way ANOVA를 확장한 것으로 두 개의 범주형 독립변수가 연속인 종속변수에 어떠한 영향을 끼치는지 알고 싶을 때 사용하는 검정방법입니다. 즉, 독립변인이 2개, 종속변인이 1개일 때 집단 간의 차이를 검정하는 것으로 한/중/일 국가간 성별과 운동량에 따른 체중비교시 독립변인은 성별/운동량이 되고 종속변인은 체중이 됩니다.

Two-way의 경우에는 두 개의 요인이 포함되므로 두 요인간의 상호작용효과도 검정에 포함됩니다. 결과적으로 3개의 귀무가설을 세우고 이를 검정하게 됩니다. 위 그림의 경우에는 1) $H_{01}:$ 성별에 따른 체중은 동일하다, 2) $H_{02}:$ 운동량에 따른 체중은 동일하다, 3) $H_{03}:$성별/운동량은 서로 독립으로 상호작용하지 않는다의 3개의 귀무가설에 대해 F 검정통계량을 각각 계산해서 수행합니다.
참조
'Theory > Statistics' 카테고리의 다른 글
| Regression - R-square (0) | 2021.04.15 |
|---|---|
| Regression - 단순 선형 회귀 (0) | 2021.04.14 |
| 파이썬으로 보는 통계 (6) - F-검정을 이용한 등분산검정 (2) | 2021.04.02 |
| 파이썬으로 보는 통계 (5) - F-분포 (0) | 2021.04.02 |
| 파이썬으로 보는 통계 (4) - 카이제곱 검정 (1) | 2021.04.02 |



