이번 포스트에서 다룰 내용은 대가 Kaiming He 저술한 비지도 학습 기반의 representation learning 알고리즘 MoCo 입니다. 지난 여러 포스트에서 다루었던 비지도 학습 기반의 representation learning 방법 중 하나로 NLP의 비지도 representation learning 방법인 BERT/GPT 의 성공을 컴퓨터 비젼 분야로 확장하려는 시도입니다.
최근 이미지 분야에서도 대조학습 (contrastive learning) 을 기반으로 한 representation learning 이 큰 성공을 거두고 있습니다. MoCo가 주목한 것은 contrastive learning 의 다양한 방법론들이 기본적으로 dictionary look-up 이라는 것입니다. 즉, 매우 많은 key가 존재하는 dictionary 에서 query로 들어온 데이터에 대해 positive key 에 대해서는 유사도가 높아야 되고 negative key 에 대해서는 유사도가 낮아야 된다는 것이죠.
MoCo는 이 개념을 확장하여 dictionary look-up 기반의 contrastive learning을 다음 그림과 같이 수행합니다. $x^{query}$에 대한 representation $q$와 dictionary에 존재하는 representation $k_0, k_1, ...$에 대하여 같은 데이터로부터 파생된 키에 대하여 유사도를 높이고 다른 데이터로부터 파생된 키에 대하여 유사도를 낮추는 방향으로 학습을 진행합니다.

원활한 학습을 위하여 1) 키가 매우 많아 다양한 negative pair를 확보할 수 있는 large dictionary와, 2) 일관된 표현을 위해 느리게 업데이트 되는 key encoder가 필요합니다.
Method
Contrastive learning as dictionary look-up
Encoded 된 query $q$와 encoded 된 키 $k_0, k_1, ...$이 있고 하나의 키 $k_+$만 $q$에 매치되는 positive key 이고 나머지 $K$개의 키는 매치되지 않는 negative key 일 때, Equation 1으로 contrastive loss를 정의할 수 있습니다.

$\tau$는 temperature 하이퍼 파라미터이며, Equation 1은 1 개의 positive 샘플과 $K$ 개의 negative 샘플에 대해 $q$를 $k_+$로 softmax를 통해 분류하는 것으로 생각할 수 있습니다. 즉, 고차원의 연속된 이미지에 대해 discrete한 dictionary를 구축하여 query에 대한 positive 샘플의 분류 확률을 높이도록 훈련한다는 것이죠.
Momentum contrast
MoCo 중요한 점은 query에 대해 representation을 추출하는 query encoder와 key에 대해 representation을 추출하는 key encoder는 별도로 정의된다는 점입니다. 특히 key encoder는 query encoder에 대해 점진적으로 변하게 되어 최대한 일관된 representation을 dictionary의 키에 담길 수 있게 하고 dictionary를 최대한 크게 구성해서 많고 다양한 negative 샘플을 볼 수 있게 해야 합니다.
먼저 dictionary를 크게 구성하기 위해서 큐로 구현합니다. 큐는 FIFO (First-In First-Out, 선입선출) 의 특성을 가진 자료구조로 큐를 dictionary로 사용함으로써 먼저 번의 mini-batch의 샘플을 negative 샘플로 재활용하며 선입선출의 특징을 이용하여 가장 오래된 샘플을 dictionary에서 제거합니다. 따라서 dictionary의 샘플들은 점진적으로 교체되게 되며 가장 오래된 샘플은 오래전 업데이트된 key encoder로부터 온 representation 이므로 제거함으로써 representation의 일관성을 유지합니다.
큐로 dictionary를 설계함으로써 dictionary 사이즈를 크게 잡을 수 있지만 큐에 담긴 모든 representation 에 대해 gradient back-propagation 을 수행할 수는 없습니다. 가장 간단한 솔루션은 query encoder $f_q$를 key encoder $f_k$로 복사하는 것이겠지만 이 방법은 dictionary의 일관성을 급격하게 해치기 때문에 결과가 좋지 않습니다. 따라서 MoCo에서는 Equation 2와 같이 momentum moving average로 $f_k$를 점진적으로 업데이트 합니다.
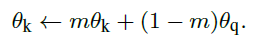
먼저 $f_k$의 파라미터 $\theta_k$와 $f_q$의 파라미터 $\theta_q$를 같게 설정하고 [0,1) 사이의 값을 가진 momentum coefficient $m$을 통해 $\theta_k$를 점진적으로 업데이트 합니다. 즉, back-propagation을 통해서는 $\theta_q$만 업데이트하게 됩니다. 따라서 dictionary 안에 있는 representation 샘플들은 각기 다른 $f_k$에 의해 추출된 representation 들이 담기게 되지만 가장 오래된 샘플들은 제거함으로써 각 representation 의 차이는 매우 작아 일관성을 유지할 수 있습니다. 실험에서도 매우 큰 $m=0.999$ 을 사용했을 때 성능이 제일 좋았다고 합니다.
Relations to previous mechanisms
MoCo에서와 달리 기존 방법들은 1) end-to-end로 dictionary까지 back-propagation으로 업데이트하거나 2) 전체 데이터에 대한 representation을 담아 놓는 memory bank 방법으로 접근했습니다.
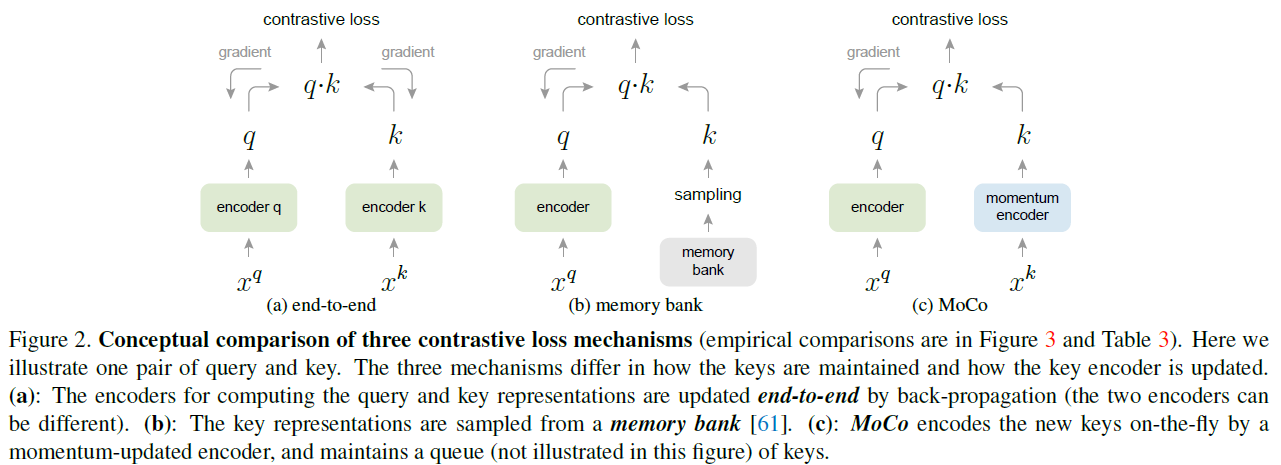
먼저 end-to-end 방식은 현재 mini-batch를 dictionary로 삼아 $f_q$와 $f_k$를 공유합니다. 하지만 이 방법은 dictionary 크기가 mini-batch 사이즈에 연관되어 GPU 메모리 상에 제약이 생기므로 다양한 negative 샘플을 활용할 수 없습니다.
Memory bank 방식은 모든 데이터의 representation 을 memory bank에 담아 랜덤하게 샘플링함으로써 dictionary를 구성하는 방식입니다. 전체 데이터를 담았으므로 dictionary가 매우 크나 memory bank 에 있는 representation은 예전에 업데이트된 encoder로부터 추출된 것이므로 일관성이 떨어집니다. 또한 MoCo가 모든 샘플에 대해 tracking 하지 않는 것에 반해 memory-bank는 메모리 측면상 비효율적이고 데이터가 수억~수십억 개가 넘어갈 경우 구현하기 쉽지 않습니다.
Algorithm

전체 알고리즘은 위와 같습니다. 현재 mini-batch에 대해서 positive 샘플을 구축하는 것을 볼 수 있으며 분류를 위한 cross-entropy loss로 훈련합니다. 또한 $f_q$, $f_k$를 업데이트 한 이후에 dictionary를 구성하는 큐 또한 오래된 샘플을 제거하면서 현재 mini-batch의 representation을 집어넣는 것을 확인할 수 있습니다.
Other details
MoCo에서는 encoder로 ResNet을 사용합니다. ResNet의 global average pooling 이후의 128 차원 출력을 $L2$로 normalize 한 것이 representation이 됩니다. Data augmentation 으로는 SimCLR 에서와 같이 crop/resize, random color jittering, random horizontal flip, random grayscale conversion 이 사용됩니다.
또한 $f_q$와 $f_k$ 각각에 대해 batch normalization을 적용하는데 일반적으로 적용할 경우 같은 배치 안 샘플들끼리 통계치가 같으므로 성능이 좋지 않다고 합니다. 이를 해결하기 위해 MoCo에서는 Shuffling batch normalization을 사용합니다. 이는 현재 mini-batch를 여러 개의 GPU에 배분하기 전 $f_k$에 들어가는 샘플의 순서를 바꾸고 $f_q$에 들어가는 샘플의 순서는 고정시키는 방법으로 각 GPU 내의 batch normalization을 위한 통계치가 키와 query에 따라 각각 달라지게 만들어 학습을 쉽게 해버리는 현상을 방지합니다.
예를 들어 GPU 0에 A라는 sub-batch가 들어가고 GPU 1에 B라는 sub-batch가 들어간다면 shuffling을 통해 A를 GPU 1으로 B를 GPU 0으로 보내 각 GPU 마다 batch normalization을 위한 통계치가 달라지게 됩니다. 통계치만 달라지게 하기 위해서 encoding 이후에 다시 원래대로 shuffle-back 합니다.
MoCo는 1개의 positive 샘플을 다른 샘플들과 구분하도록 하는 instance discrimination pretext task를 통해 학습합니다. 따라서 하나의 배치 안의 다른 샘플들을 보지 않고 샘플 각각이 독립적으로 학습되는 것이 더 좋은 representation 을 얻는 것이 가능하므로 GPU 별 batch normalization 통계를 바꾸는 것이라 설명하고 있습니다. 자세한 내용은 Shuffling BN을 구현한 포스트를 참고하시길 바랍니다. (명확하게 이해는 안되네요)
참조
다음 포스트
[Machine Learning/Unsupervised Learning] - Self-Supervised Learning - MoCo (2)
'Machine Learning Tasks > Self-Supervised Learning' 카테고리의 다른 글
| Self-Supervised Learning - MoCo v2 (0) | 2021.04.16 |
|---|---|
| Self-Supervised Learning - MoCo (2) (0) | 2021.04.16 |
| Self-Supervised Learning - SimCLRv2 (2) (0) | 2021.04.09 |
| Self-Supervised Learning - SimCLRv2 (1) (0) | 2021.04.03 |
| Self-Supervised Learning - BYOL (2) (0) | 2021.04.03 |



