이전 포스트
[Machine Learning/Unsupervised Learning] - Self-Supervised Learning - SimCLRv2 (1)
Experiment
Settings
Semi-supervised learning 실험을 위해 ImageNet 데이터셋에서 랜덤하게 뽑힌 1%/10% 데이터를 일부분의 labeled data로 사용합니다. 다른 representation learning 성능 측정 방식과 마찬가지로 고정된 representation위에 linear classifier를 탑재해 훈련시키는 linear evaluation을 수행하였으며 배치 사이즈가 크기 때문에 LARS 옵티마이저를 사용합니다.
Self-supervised pretraining을 위해서 4096의 배치 사이즈와 128개의 TPU를 사용하여 800 epoch 동안 훈련시킵니다. Learning rate는 epoch의 5% 동안 증가시킨 이후 감소시키며 projection head로는 3층의 MLP를 사용합니다. 또한 SimCLR과 같이 random crop, color distortion, Gaussian blur의 augmentation 기법을 사용합니다.
Fine-tuning을 위해서 projection head의 첫 번째 층으로부터 fine-tuning을 수행합니다. Fine-tuning 시에는 learning rate를 pretraining 시보다 감소시키며 배치사이즈는 1024를 사용합니다. 또한 1% semi-supervised 시에는 60 epoch, 10% semi-suprvised 시에는 30 epoch 동안 fine-tuning 시킵니다.
Distillation은 projection head를 제외한 teacher network와 student network가 같은 구조를 가지는 self-distillation과 teacher network보다 훨씬 적은 파라미터를 가진 student network를 훈련시키는 big-to-small distillation 을 수행합니다. Fine-tuning과 distilaltion 에서는 random crop과 horizontal flip만 사용합니다.
Bigger models are more label-efficient
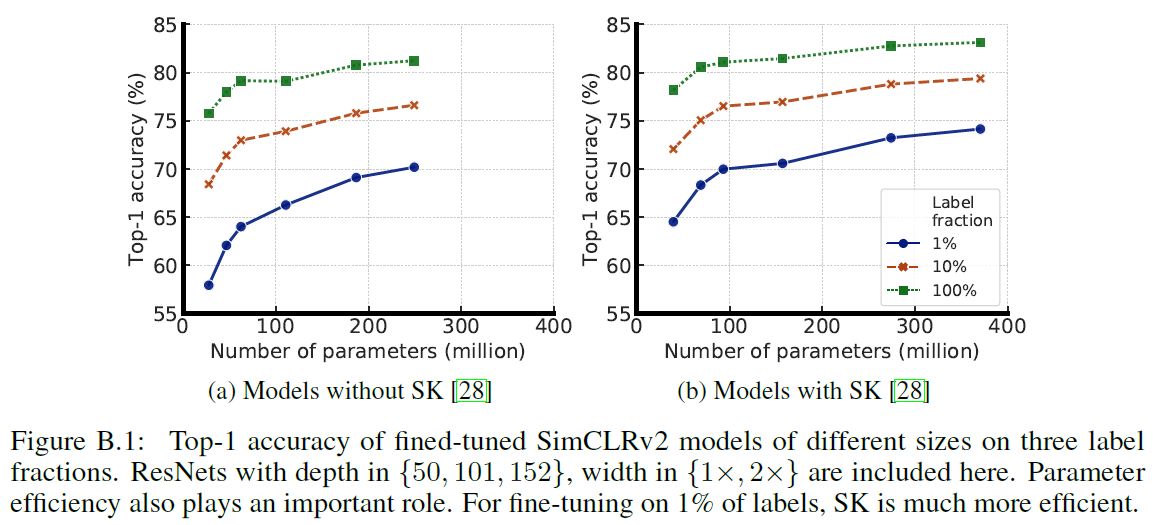
모델의 크기에 따른 효과를 알아보기 위해 ResNet의 깊이와 너비 (depth/width) 를 변화시키고 파라미터의 효율적인 사용을 위한 selective kernels (SK) 을 사용합니다. 실험에서 사용된 가장 작은 모델은 ResNet-50이고 가장 큰 모델은 ResNet-152 (3x+SK) 입니다.

위의 Table 1을 보면 depth/width를 증가시킬 때 파라미터 수가 증가하지만 성능이 매우 증가함을 확인할 수 있습니다. 또한 selective kernels 를 사용했을 때도 성능이 좋아집니다. 또한, 모델 크기에 따른 성능 증가는 self-supervised에 더 효과적임을 알 수 있고 1% fine-tuning의 경우 성능이 무려 18% 증가했습니다.. (supervised의 경우는 고작 4% 증가하는데 그쳤습니다.) 마지막으로 ResNet-152 2x 와 3x 가 파라미터의 수가 거의 배로 차이나지만 성능이 포화된 것을 확인할 수 있습니다.

Figure 4를 보면 파라미터가 많은 큰 모델일수록 label 효율이 더 좋음을 알 수 있습니다. 모델의 사이즈가 클수록 성능이 증가하고 특히 semi-supervised learning이 큰 모델의 효과를 더 보고 있는 것을 알 수 있습니다.
마지막으로 파라미터 efficiency를 위한 selective kernels 의 효과도 영향을 미치는 것을 알 수 있습니다. 특히, 파라미터 efficiency를 위한 테크닉들은 같은 수의 파라미터로 더 큰 모델의 효과를 낼 수 있기 때문이라고 생각되며 group convolution과 같은 다른 파라미터 efficient 한 컨볼루션 방법도 큰 효과를 보일 수 있을 것이라 추측됩니다.
Bigger/depper projection heads improve representation learning
Fine-tuning에서의 projection head의 크기에 따른 영향을 알아보기 위해 projection head를 2~4층의 MLP로 설계하여 실험합니다. 또한 projection head의 입력 representation과 첫 번째 층의 representation에서 fine-tuning을 할 때의 성능 차이를 실험합니다.
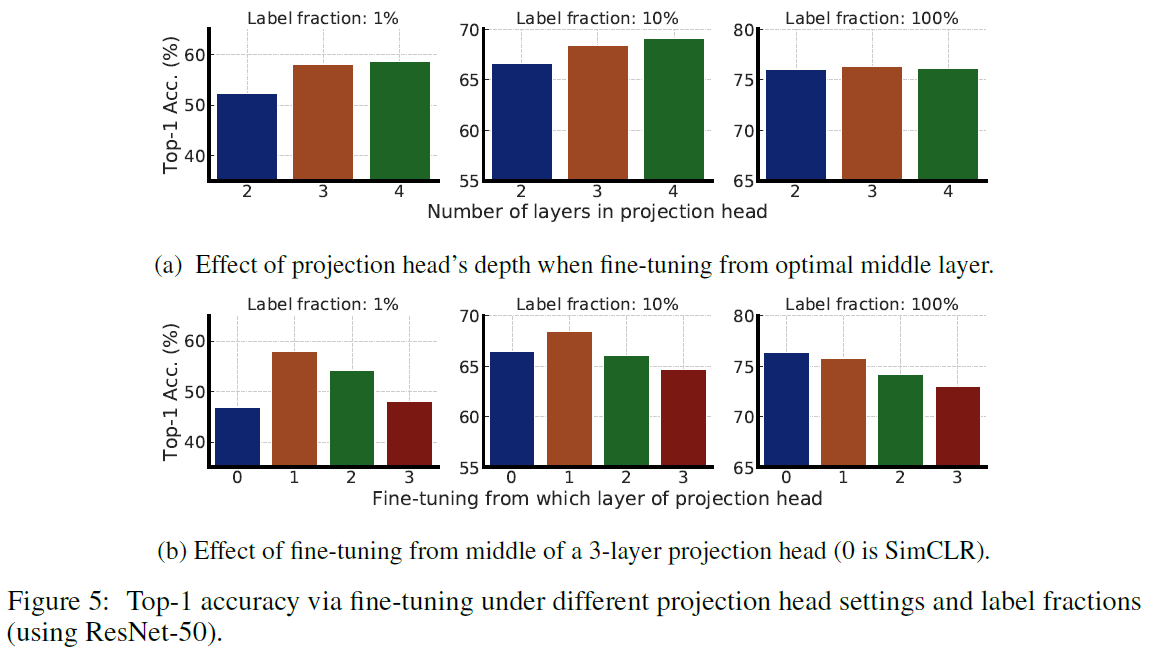
결과적으로 깊은 projection head를 쓰면서 첫 번째 층에서부터 fine-tuning을 할 때 성능이 제일 좋습니다. 또한 넓은 ResNet일 수록 projection head 또한 넓어지기 때문에 projection head가 깊어질때의 효과는 미미합니다.
Distillation using unlabeled data improves semi-supervised learning
Distillation은 일반적으로 teacher network의 결과와 labeled data를 함께 사용해서 훈련합니다. Table 2를 보면 unlabeled data를 활용한 distillation 만으로도 괜찮은 성능이 나온 것을 확인할 수 있습니다.

특히 distillation을 통해 기존의 fine-tuned 모델을 개량할 수 있습니다. Task-specific하게 더욱 작은 모델을 효율적으로 훈련시킴으로써 teacher network의 knowledge transfer가 잘 이루어졌다고 생각할 수 있습니다. Figure 6를 보면 big-to-small distillation의 경우 모델 efficiency를 굉장히 높였고 projection head를 제외한 self-ditillation 에서도 같은 파라미터 수에서 성능이 더 증가했습니다. 참고로 작은 ResNet의 경우 최대한의 성능을 얻기 위해 큰 모델을 먼저 self-distillation을 하고 이것을 teacher network로 삼아 big-to-small distillation을 수행했다고 합니다.
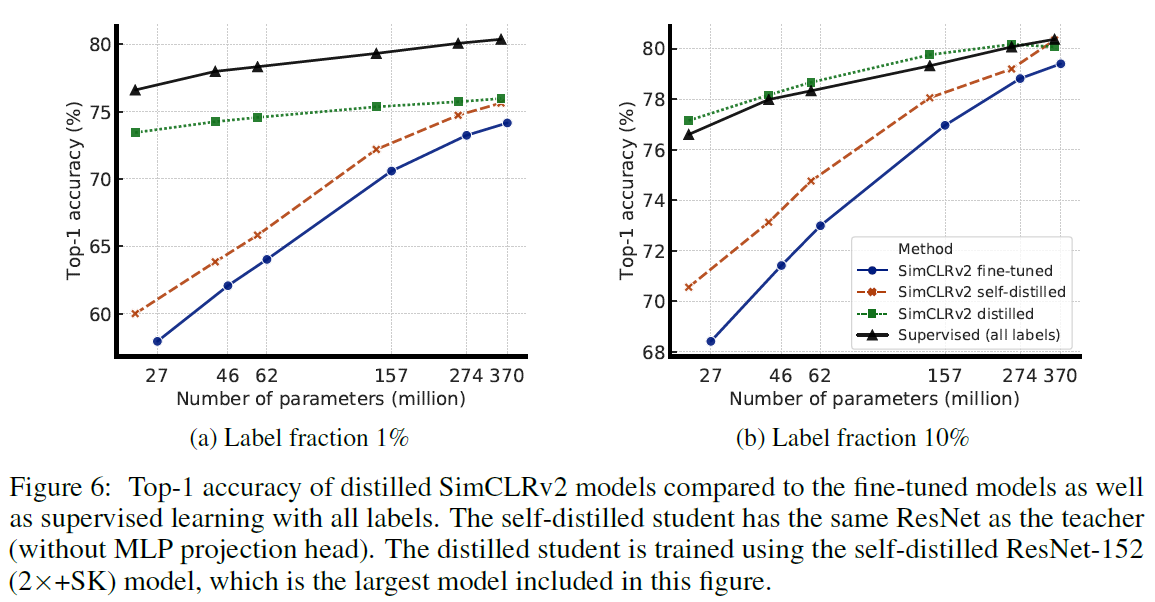
마지막으로 다른 self-supervised learning 방법과의 성능 비교입니다.

Discussion
Unlabeled data를 활용한 pretraining을 수행 후 다양한 task에 맞춰 fine-tuning하는 방법은 BERT를 위시한 NLP에서 큰 성공을 거두었습니다. SimCLRv2는 이러한 패러다임을 컴퓨터 비젼에 대해 잘 적용하여 기존 방법론들보다 높은 성능을 거두었습니다.
Self-supervised learning의 가장 큰 특징은 일관적으로 큰 모델에 대해서 성능 향상이 크다는 점입니다. 지도 학습을 수행할 때 일반적으로 큰 모델은 과적합을 일으킨다는 사실을 생각해볼 때, 비지도 학습에서는 큰 모델이 더 일반화된 feature를 학습할 수 있다는 점은 특기할만 합니다. 또한 큰 모델을 구성하더라도 distillation을 통해 모델 효율성을 높여 컴팩트한 모델을 지속적으로 만들 수 있습니다.
비지도 학습을 통해 일반화된 representation을 학습하고 task-specific하게 fine-tuning 하는 방법으로 수행하는 semi-supervised learning은 디테일한 라벨 정보를 얻기 힘든 다양한 분야에서 효과적으로 사용할 수 있을 것이라 생각합니다.
'Machine Learning Tasks > Self-Supervised Learning' 카테고리의 다른 글
| Self-Supervised Learning - MoCo (2) (0) | 2021.04.16 |
|---|---|
| Self-Supervised Learning - MoCo (1) (0) | 2021.04.15 |
| Self-Supervised Learning - SimCLRv2 (1) (0) | 2021.04.03 |
| Self-Supervised Learning - BYOL (2) (0) | 2021.04.03 |
| Self-Supervised Learning - BYOL (1) (0) | 2021.03.28 |



