Self-supervision을 이용한 이미지 representation을 추출하는 분야는 그 포텐셜로 인해 Google, Facebook을 필두로 깊게 연구되고 있습니다. 이미지의 자가 라벨을 이용한 self-supervision의 여러 방법론 중에서 같은 이미지의 다르게 augmented 된 positive pair의 거리를 줄이고 다른 이미지의 augmented 이미지인 negative pair의 거리를 늘리는 contrastive learning이 높은 성능으로 인해 대세로 자리잡았는데요, contrastive learning은 효과적인 학습을 위한 많은 negative pair가 필요하고 (일반적으로 큰 batch size를 잡습니다) image augmentation 종류에 영향을 많이 받습니다.
이번 포스트의 주제는 구글 Deepmind의 Boostrap Your Own Latent입니다. BYOL은 negative samples를 사용하지 않고 두 개의 network를 이용해 반복적으로 network의 출력을 bootstrap하면서 높은 성능을 달성했습니다. 또한, 배치 사이즈나 image augmentation 종류에 더욱 강건합니다.
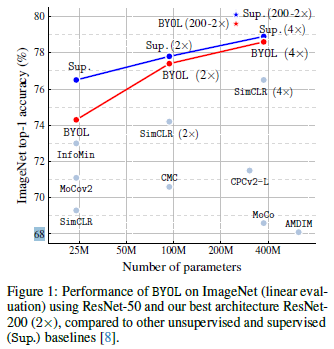
Figure 1의 성능을 보았을 때, 기존 self-supervised 방법론에 비해 더 우수한 성능을 보이고 파라미터가 많아질수록 지도학습 성능에 근접함을 볼 수 있습니다.
Method
일반적인 self-supervised 방법론은 한 이미지의 다양한 view (다양한 augmentation)를 예측함으로서 공통된 representation을 학습하는 방법으로 이루어집니다. 하지만 이러한 방법은 모든 view에 대해 같은 representation을 도출하는 collapsed representations 현상이 발생할 수 있는데요. 이를 타개하기 위해 contrastive learning은 augment 클래스를 예측하는 문제에서 positive pair와 negative pair를 구분하는 discrimination 문제로 바꿉니다. 즉, 같은 이미지로부터 파생된 positive pair와 서로 다른 이미지인 negative pair를 구분함으로써 collasped representations를 방지하겠다는 것이죠.
이 방법은 positive/negative 구분 문제를 더 효과적으로 강제하기 위해 근본적으로 많은 negative examples가 필요하며, 이를 위해 매우 큰 배치 사이즈를 사용하거나 semi-hard negative examples를 별도의 과정으로 추출해야하는 과정을 거칩니다.
BYOL의 기본 insight는 이렇습니다. Collapse를 방지하기 위한 직관적인 방법은 랜덤하게 초기화된 neural network A를 사용하여 linear evaluation을 위한 representation을 추출하는 것입니다. 당연히 성능이 낮을 수밖에 없습니다. 하지만 재밌는 점은 또다른 neural networks B가 A의 출력을 대상으로 학습시킨 결과 linear evaluation의 성능이 비약적으로 상승했다는 점입니다. 이것이 BYOL의 핵심 motivation입니다.

BYOL은 위 그림을 반복적으로 수행하며 A를 target networks, B를 target networks의 출력을 예측하는 online networks라 칭합니다. 즉, online networks를 target networks의 representation을 예측하도록 반복적으로 학습시켜 양질의 representations 뽑아내도록 합니다. 이러한 bootstrapping 과정을 반복적으로 수행하면서 target networks의 파라미터는 online networks의 파라미터와의 moving exponential average로 천천히 업데이트 시킵니다.
Description
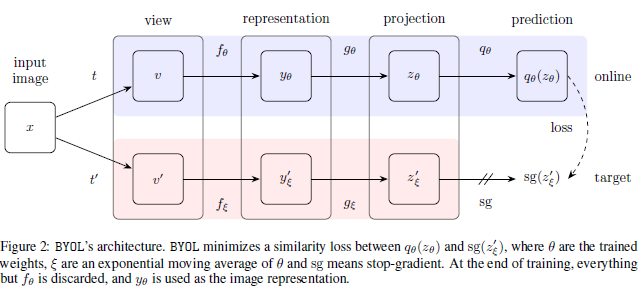
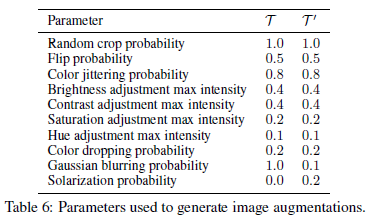
BYOL의 목표는 Figure 2의 representation $y_\theta$를 학습하는 것입니다. 이를 위해 online / target network로 학습을 진행합니다. Online network는 encoder $f_\theta$, projector $g_\theta$, predictor $q_\theta$로 이루어져 있으며, target network는 online network와 똑같은 구조를 가지며 online network의 regressoin target을 제공합니다. (위 그림의 network A의 역할을 하는 것이죠) Target network의 파라미터 $\xi$는 online network의 파라미터 $\theta$와의 exponential moving average로 결정됩니다.
먼저 이미지 $x$에 대해 두 가지 transformation이 적용되며, $t$와 $t'$은 미리 정해진 image augmentation set $T$와 $T'$에서 추출됩니다. Online network는 $z_\theta=g_\theta (y)$ projection을 추출하고 target network는 $z'_\xi=g_\xi (y')$ projection을 추출합니다. 이때, online network는 target projection $z'_\xi$를 예측하기 위해 online projection $z_\theta$에 prediction layer를 거친 $q_\theta (z_\theta)$를 출력하여, $q_\theta (z_\theta)$와 $z'_\xi$가 같도록 목적 함수를 Equation 1 같이 설계합니다.
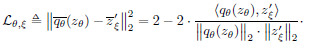
Equation 1을 보면 $q_\theta (z_\theta)$와 $z'_\xi$가 각각 $l_2$ normalize 된 것을 볼 수 있으며, predictor는 online network에만 적용됩니다. 또한, $L_{\theta,\xi}$를 대칭화시키기 위해 사용한 augmentation $t, t'$을 바꾸어서 loss를 한 번 더 계산해 더해줍니다. 즉, $L_{\theta,\xi}^{BYOL}$은 $L_{\theta,\xi} + \tilde{L}_{\theta,\xi}$가 되겠죠.
BYOL은 online network 파라미터 $\theta$에 대해서만 gradient descent를 적용하고 $\xi$는 $\theta$와의 moving average로 결정됩니다. 위의 Figure 2에서 target network 부분은 stop gradient 인 것을 볼 수 가 있죠. 최종적으로 $\theta$, $\xi$는 Equation 2와 같이 업데이트 됩니다. $\tau$는 decay rate이고 $\eta$는 learning rate입니다.

훈련이 끝난 이후에는 $f_\theta$만 남기고 나머지는 삭제합니다. 즉, 최종적인 representation은 $f_\theta$가 되는 것이죠. 전체적인 알고리즘은 밑과 같습니다.

BYOL's behavior
BYOL은 negative examples를 활용하지 않아 명시적으로 collapse 를 방지하는 항이 없어 collasped constant representation으로 수렴하지 않을까라고 생각할 수 있지만 저자들은 실험에서 그러한 현상은 발생한 적이 없다고 합니다. 즉, $L_{\theta,\xi}^{BYOL}$ 이 $\theta, \xi$ 모두에 대해 최소화되도록 동작하지 않기 때문이라고 가정합니다. (여기서 말하는 최소화는 $\theta, \xi$ 모두에 대해 $L$이 최소화되는 지점으로 collapsed constant representation 입니다)
만약, BYOL의 predictor가 Equation 3과 같이 optimal 하다고 가정한다면 ($q_\theta=q^{*}$), $\theta$의 업데이트는 Equation 4와 같이 $z_\theta$가 주어졌을 때의 $z'_\xi$의 variance인 expected conditional variance 방향으로 정해집니다.
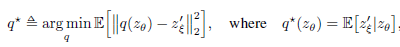

Conditional variance $Var(Y|X)$는 $X$로 $Y$를 예측한 이후의 남은 variance이고 Equation 6에서 볼 수 있듯이 expected conditional variance $E[Var(Y|X)]$는 $X$로 $Y$를 예측한 이후의 irreducible error인 것을 감안했을 때, optimal predictor라면 이 variance가 최대한 작아져야 합니다.
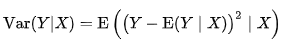
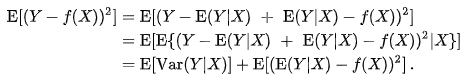
모든 random variable $X,Y,Z$에 대해 $Var(X|Y,Z) \geq Var(X|Y)$이고 $X$를 target projection, $Y$를 online projection, $Z$를 predictor와 같은 additional variability라 가정했을 때, $Z$ (predictor)를 제거하는 것은 conditional variance를 줄일 수 없습니다. 따라서 이는 online network에 additional predictor를 붙인 이유라고 생각할 수 있습니다.
또한, 상수 $c$에 대해 $Var(z'_\xi |z_\theta) \geq Var(z'_\xi|c)$이다 보니 BYOL은 $z_\theta$가 constant features로 가지 않도록 동작하게 되며, 이러한 의미로 BYOL이 의도치 않은 수렴점에 도달한다고 하여도 expected conditional variance가 클 것이니 불안정하다고 주장합니다.
BYOL은 $\xi$를 $\theta$와 가깝게 만들어 online projection상에서 포착된 다양성을 target projection에 반영하려 합니다. 이때, $\theta$를 $\xi$로 hard copy해도 online projection의 다양성을 그대로 가져올 수 있습니다. 하지만 이럴 경우 target network가 급격하게 변하기 때문에 online network의 optimal predictor 전제 조건이 깨질 우려가 있습니다. 따라서 predictor의 near-optimality를 만족시키기 위해 $\xi$는 $\theta$와의 moving average로 천천히 움직이도록 결정됩니다.
이 부분은 전반적으로 저자의 직관적이 해석이 위주이다 보니 저자의 의도를 구체적으로 알기가 쉽지 않습니다만, 결론적으로는 BYOL이 online network에 additional predictor를 사용함으로써 conditional variance를 줄이면서 동시에 $\xi$를 moving average로 업데이트하여 predictor가 near-optimality를 유지하게 함으로써 BYOL이 collapsed representation으로 수렴하지 않는다는 것을 사고이론적으로 풀어낸 것이라 생각합니다.
Implementation details
BYOL은 SimCLR과 같은 종류의 image augmentation인 1) 랜덤 cropping이후의 resize, 2) color distortion (brightness, contrast, saturation, hue, grayscale conversion), 3) Gaussian blur를 사용합니다. 전체 augmentation 종류는 밑과 같고 Figure 2의 augmentation $T,T'$은 아래 augmentation 순서대로 확률에 따른 조합으로 (Table 6) 이루어집니다.

Encoder로는 ResNet-50를 사용하며, representation $y$는 ResNet의 마지막 average pooling layer의 아웃풋으로 정해집니다. (feature dimension 2048) 또한, projector는 4096-256 차원을 가진 MLP로 구성되고 내부 레이어에는 batch normalization과 ReLU가 사용됩니다. Predictor는 projector와 같은 network를 사용합니다.
Target network의 $xi$의 moving update를 위한 $\tau$는 0.996으로부터 시작하여 Equation 7과 같이 iteration에 따라 1까지 증가합니다. Equation 7의 $k$는 현재 training step, $K$는 전체 training step입니다. 또한, 배치 사이즈를 4096으로 하여 512개의 TPU로 학습시켰다고 합니다.

참조
다음 포스트
[Machine Learning/Unsupervised Learning] - Self-Supervised Learning - BYOL (2)
'Machine Learning Tasks > Self-Supervised Learning' 카테고리의 다른 글
| Self-Supervised Learning - SimCLRv2 (2) (0) | 2021.04.09 |
|---|---|
| Self-Supervised Learning - SimCLRv2 (1) (0) | 2021.04.03 |
| Self-Supervised Learning - BYOL (2) (0) | 2021.04.03 |
| Self-Supervised Learning - SimCLR (2) (0) | 2021.03.23 |
| Self-Supervised Learning - SimCLR (1) (0) | 2021.03.23 |



