최근 대용량의 라벨링이 필요한 supervised learning을 보완하는 self-supervised learning이 각광받고 있습니다. Self-supervised learning 이란 입력의 해당하는 라벨 없이 입력 그 자체만으로 만든 라벨에 대해 discriminative하게 훈련시켜 데이터의 representation을 학습하는 방법입니다. 대표적으로 이미지에 적용한 geometric transformation의 종류를 예측하는 방법으로 이미지의 representation을 얻는 방법이 있습니다.
기존의 이러한 방법들은 데이터를 통해 해결하고자 하는 본래의 task 이전에 자가 라벨을 이용한 pretask를 수행하여 데이터의 representation을 학습하지만 이러한 pretask는 논문마다 heuristic하게 적용하여 일반화가 어렵습니다. 이번 포스트에서 다룰 논문은 self-supervised learning의 한 종류인 contrastive learning을 통해 간단하게 visual representation을 얻을 수 있는 framework를 제안합니다.
이를 통해 SimCLR은 ImageNet에 대한 self-supervised/semi-supervised learning에서 가장 높은 성능을 거두었으며, contrastive learning으로 representation을 학습한 이후 ImageNet의 1%의 라벨 데이터로 fine-tuning 하였을 때또한 기존 방법들에 비해 높은 성능을 보였습니다.
Method
The contrastive learning framework
Contrastive learning의 기본 원리는 여러 이미지들 중 비슷한 이미지 pair (positive pair)를 서로 가깝게 하면서 이 둘을 비슷하지 않은 이미지 pair (negative pair)에서 멀리 떨어지게 하는 것으로 SimCLR 에서는 서로 다르게 augmented 된 두 개의 이미지 pair에 대해 positive pair로 작용하도록 동작하게 함으로써 representation을 학습합니다. 전체 framework는 다음과 같습니다.
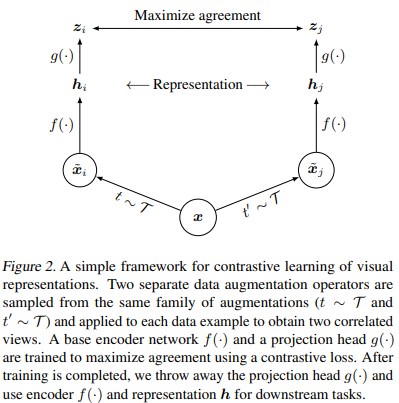
먼저 입력 $x$에 대해 랜덤하게 두 개의 transformation을 $t, t'$을 뽑아내어 적용합니다 ($\tilde{x}_i$, $\tilde{x}_j$). Transformation set $\mathcal{T}$는 random cropping, random color distortion, random Gaussian blur 를 사용합니다. 그 이후 transformed 된 이미지에 대해 base encoder $f$를 적용하여 representation을 추출합니다. $f$는 ResNet을 사용하며, $h_i=f(\tilde{x}_i) \in R^d$로 average pooling layer의 출력을 사용합니다.
$f$이후에 projection head라는 non-linear 함수 $g$를 적용합니다. $g$는 2-layer MLP로 $z_i$=$g(h_i)$=$W_2 ReLU(W_1 h_i)$를 출력하고 출력한 $z_i, z_j$에 대해 contrastive loss를 적용합니다. Contrastive loss는 $\tilde{x}_i, \tilde{x}_j$를 positive pair로 강제하는 함수로서 transformed 된 여러 이미지 $\tilde{x}_k$가 있을 때, $\tilde{x}_j$를 $\tilde{x}_{k\neq i}$로부터 찾아내게끔 합니다.
Contrastive loss
Contrastive loss는 이미지 pair에 적용되므로 $N$개의 데이터로 이루어진 미니배치가 존재할 때, 각 데이터 별로 랜덤하게 두 개의 transformation을 적용하여 총 $2N$개의 데이터를 구성합니다. 미니배치 안의 하나의 데이터 $x$에 대해 두 개의 transformation을 적용한 $\tilde{x}_i$, $\tilde{x}_j$를 positive pair로 구성하고 나머지 $2(N-1)$개의 데이터는 negative examples로 취급합니다.
Positive/negative 를 측정하기 위해 cosine-similarity ($sim(u,v)=u^T v/ |u||v|$)를 사용하며, positive pair $(i,j)$에 대한 contrastive loss는 다음과 같습니다.

$\tau$는 temperature parameter 이며, 하나의 미니배치에 대해 모든 positive pair에 대해 contrastive loss가 적용됩니다. 논문에서는 이 loss를 NT-Xent (Normalized Temperature-scaled Cross Entropy loss) 라 표기합니다.
이 loss 항을 볼 때, positive pair $(i,j)$에 대해서는 전체 cosine-similarity 합에서 $j$에 대한 cosine-similarity가 줄어들도록 작용하므로 $i$의 $j$에 대한 cross entropy 함수로 볼 수 있습니다. 전체 알고리즘은 다음과 같으며, 마지막 부분에 $(i,j)$와 $(j,i)$에 동시에 constrastive loss를 적용하는 것을 볼 수 있습니다.

Training with large batch size
SimCLR은 256부터 8192까지의 큰 배치 사이즈를 사용합니다. 8192의 배치 사이즈를 사용한다면 positive pair당 16382개의 negative examples가 생기게 되겠죠. 이러한 큰 배치 사이즈에 대해서는 일반적인 SGD/Momentum optimizer로 훈련하게 되면 불안정해집니다. 따라서 LARS 라는 (Large Batch Training of Convolutional Networks) optimizer를 사용합니다.
Evaluation protocol
$f$를 contrastive learning으로 학습하는 unsupervised 과정은 ImageNet의 데이터에 대해 수행하였고 최종 성능 평가를 위해서는 추출한 feature representation에 linear classifier를 학습시켜 성능을 평가하는 linear evaluation 방법이 사용됩니다. 훈련을 위한 기본 세팅으로는 $f$로 ResNet-50을, $g$로는 2-layer MLP를 사용했으며 $z$의 차원으로는 128을 사용했습니다.
마지막으로 사용된 데이터 augmentation으로는
1) random crop and resize 가 사용됩니다. Crop할 비율은 0.08에서 1까지 사이의 값으로 결정되며 다시 ImageNet 사이즈인 224x224로 리사이즈됩니다. 또한, 리사이즈 이후 50% 확률로 horizontal/vertical flip을 적용합니다.
2) Color distortion 이 사용됩니다. Color distortion은 색깔을 지우거나 더 진하게 만드는 작업으로 Tensorflow나 Pytorch에 다음과 같이 구현되어 있습니다.

3) Gaussian blur가 사용됩니다. Gaussian kernel의 $\sigma$는 0.1에서 2사이의 값으로 뽑히며 kernel 크기는 이미지 크기의 10%로 설정합니다.
다음 포스트
[Machine Learning/Unsupervised Learning] - Self-Supervised Learning - SimCLR (2)
'Machine Learning Tasks > Self-Supervised Learning' 카테고리의 다른 글
| Self-Supervised Learning - SimCLRv2 (2) (0) | 2021.04.09 |
|---|---|
| Self-Supervised Learning - SimCLRv2 (1) (0) | 2021.04.03 |
| Self-Supervised Learning - BYOL (2) (0) | 2021.04.03 |
| Self-Supervised Learning - BYOL (1) (0) | 2021.03.28 |
| Self-Supervised Learning - SimCLR (2) (0) | 2021.03.23 |



