Deep neural networks 는 마지막 단의 목적함수에 대한 파라미터 별 기울기를 통한 gradient descient 방식으로 업데이트 됩니다. 이때 편미분의 chain-rule 을 이용한 back-propagation (neural networks 의 뒷 단에서 앞 단 순으로 기울기가 계산됩니다) 을 이용해 deep neural networks 를 구성하는 모든 파라미터의 목적함수에 대한 기울기를 구할 수 있습니다.
Pytorch 에는 hook 이라는 기능이 있어 매 layer 마다 print 문을 통해 확인하지 않아도 각 층의 activation/gradient 값을 확인할 수 있습니다. 먼저 Figure 1과 같은 2-layer 의 MLP 를 구성해보도록 하겠습니다.

import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(2,2)
self.s1 = nn.Sigmoid()
self.fc2 = nn.Linear(2,2)
self.s2 = nn.Sigmoid()
self.fc1.weight = torch.nn.Parameter(torch.Tensor([[0.15,0.2],[0.250,0.30]]))
self.fc1.bias = torch.nn.Parameter(torch.Tensor([0.35]))
self.fc2.weight = torch.nn.Parameter(torch.Tensor([[0.4,0.45],[0.5,0.55]]))
self.fc2.bias = torch.nn.Parameter(torch.Tensor([0.6]))
def forward(self, x):
x= self.fc1(x)
x = self.s1(x)
x= self.fc2(x)
x = self.s2(x)
return x
net = Net()
print(net)
Neural networks 의 파라미터가 우리가 할당한 값으로 초기화되었는지 확인해보면,
print(list(net.parameters()))
값이 제대로 할당되어 있는 것을 볼 수 있습니다. 이후 특정 데이터에 대해 출력과 타겟 간의 Mean Squared Error 를 확인해 보겠습니다.
data = torch.Tensor([0.05, 0.1])
# output of last layer
out = net(data)
target = torch.Tensor([0.01,0.99]) # a dummy target
criterion = nn.MSELoss()
loss = criterion(out, target)
print(loss)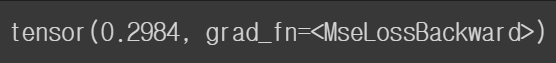
그럼 forward/backward 패스 시 각 layer의 값을 확인할 수 있는 간단한 hook 클래스를 만들어 보겠습니다.
class Hook():
def __init__(self, module, backward=False):
if backward == False:
self.hook = module.register_forward_hook(self.hook_fn)
else:
self.hook = module.register_backward_hook(self.hook_fn)
def hook_fn(self, module, input, output):
self.input = input
self.output = output
def close(self):
self.hook.remove()이후 각 layer 마다 hook 를 등록합니다. nn.Modules 를 상속받은 모델은 net._modules 속성으로 각 layer 의 이름과 layer 객체를 확인할 수 있습니다. Forward/backward 모두 hook 를 등록합니다. 목적함수에 대한 backward() 함수는 내부적으로 scalar 값에 대해서만 동작하므로 backward 함수 입력에 out 의 차원만큼 torch.tensor([1,1]) 을 넣어주어야 합니다.
hookF = [Hook(layer[1]) for layer in list(net._modules.items())]
hookB = [Hook(layer[1],backward=True) for layer in list(net._modules.items())]
# run a data batch
out = net(data)
# backprop once to get the backward hook results
out.backward(torch.tensor([1,1], dtype=torch.float), retain_graph=True)이후 forward/backward 패스에 대해 입력/출력을 확인할 수 있습니다. 특이한 점은 forward / backward hook 모두 input 부분은 튜플로 이루어져 있다는 것입니다.
print('***'*3+' Forward Hooks Inputs & Outputs '+'***'*3)
for hook in hookF:
print(hook.input)
print(hook.output)
print('---'*17)
print('\n')
print('***'*3+' Backward Hooks Inputs & Outputs '+'***'*3)
for hook in hookB:
print(hook.input)
print(hook.output)
print('---'*17)
그렇다면 forward/backward 훅에 대한 입력과 출력을 무엇을 뜻할까요? 먼저 염두해 두어야 할 점은 backward pass 는 뒷단부터 시작하므로 forward pass 와 방향이 반대라는 점입니다. Forward pass 의 경우 layer 2의 직전 layer는 layer 1이 되고 backward pass 의 경우 layer 2의 직전 layer는 layer 3이 되게 됩니다.
layer.register_forward_hook(module, input, output)먼저 forward pass 부터 살펴보면, register_forward_hook 의 input은 직전 layer의 출력, output 은 현재 layer의 출력이 됩니다.
layer.register_backward_hook(module, grad_in, grad_out)"grad_out" 은 forward pass 로부터 계산된 현재 layer 의 출력에 대한 모델 출력의 기울기입니다. 따라서 마지막 layer 에 대해서는 모델 출력의 자기 자신에 대한 기울기이므로 [1,1] 이 되게 됩니다. "grad_in" 은 "grad_out" 과 "grad_out" 에 대한 해당 layer 입력의 기울기를 곱한 값으로 chain-rule 에 의한 다음 layer 의 "grad_out" 이 됩니다. 이를 마지막 출력에 대해 확인해 보겠습니다.
forward_output = np.array([0.7514, 0.7729])
grad_in = np.array([1,1]) # sigmoid layer
# grad of sigmoid(x) wrt x is: sigmoid(x)(1-sigmoid(x))
grad_out = grad_in*(forward_output*(1-forward_output))
print(grad_out)
위의 backward hook 마지막 결과와 동일한 것을 확인할 수 있습니다. 세번째 층인 fully-connected layer 에 대해서 확인해보면 직전 층에서 계산된 기울기를 grad_out 입력으로 받고 bias 항이 더해져있으므로 해당 층의 weight 가 곱해지는 입력노드와 bias 항이 더해지는 노드에 대한 두 개의 기울기를 "grad_in" 으로 리턴합니다. 입력노드에 대한 기울기는 $Wx+b$ 이므로 "grad_out" 입력에 weight 를 곱하여 구할 수 있습니다.
weight2 = list(net.parameters())[2]
# the 3th layer - linear
print([0.1868, 0.1755]) # grad_input * (grad of Wx+b = (w1*x1+w2*x2)+b wrt W)
print(0.1868 + 0.1755) # grad of Wx+b wrt b
grad_in = torch.Tensor(grad_out)
grad_out = grad_in.view(1,-1) @ weight2
grad_out # grad of layer output wrt input: wx+b => w
두 번째 sigmoid 에 대해서도 확인해보면 위의 hook 결과와 동일합니다.
# the 2nd layer - sigmoid
forward_output=np.array([0.5933, 0.5969])
grad_in=np.array([0.1625, 0.1806])
grad_in*(forward_output*(1-forward_output)) # grad * (grad of sigmoid(x) wrt x)
Fully-connected layer 의 backward hook 부분을 보면 해당층 입력 / 출력 기울기가 서로 같은 것을 볼 수 있습니다. 이는 분명한 오류이고 파이토치 포럼에서도 nn.Module 에 대한 backward hook 가 제대로 동작하지 않는다고 합니다. (2019년 10월 기준)
'Machine Learning Models > Pytorch' 카테고리의 다른 글
| Pytorch - embedding (0) | 2021.06.23 |
|---|---|
| Pytorch - autograd 정의 (1) | 2021.06.02 |
| Pytorch - gather (0) | 2021.06.01 |
| Pytorch - scatter (3) | 2021.06.01 |
| Pytorch - backward(retain_graph=True) (1) (4) | 2021.05.09 |
