임베딩 (Embedding) 이라는 말은 자연어처리 분야에서 (NLP) 매우 많이 등장하는 단어로 이산적, 범주형인 변수를 sparse한 one-hot 인코딩 대신 연속적인 값을 가지는 벡터로 표현하는 방법을 말합니다. 즉, 수많은 종류를 가진 단어, 문장에 대해 one-hot 인코딩을 수행하면 수치로는 표현이 가능하겠지만 대부분의 값이 0이 되버려 매우 sparse 해지므로 임의의 길이의 실수 벡터로 밀집되게 표현하는 일련의 방법을 임베딩이라 하고 각 카테고리가 나타내는 실수 벡터를 임베딩 벡터라고 합니다.

Pytorch, Tensorflow 딥러닝 프레임워크는 이러한 임베딩을 쉽게 할 수 있는 api 함수를 제공합니다. 임베딩을 할 전체 크기에 대해 각 카테고리 별로 지정한 차원을 가지는 임베딩 벡터를 저장한 lookup 테이블로 학습 가능한 파라미터를 선언하면서 forward 진행 시 지정한 인덱스에 따른 임베딩 벡터를 추출합니다.
torch.nn.Embedding
주요한 파라미터는 다음과 같습니다.
| Parameters | Type | Description |
| num_embeddings | int | 임베딩 벡터를 생성할 전체 범주 개수. |
| embedding_dim | int | 임베딩 벡터의 차원. |
| padding_idx | int, optional | 지정된 인덱스에 대한 임베딩 벡터에 대해서는 훈련시 파라미터 업데이트가 되지 않습니다. |
| max_norm | float, optional | 특정 실수가 주어지고 임베딩 벡터의 norm이 이 값보다 크다면 norm이 이 값에 맞추어지도록 정규화됩니다. |
| norm_type | float, optional | $p$-norm의 $p$값으로 디폴트는 2입니다. |
다음과 같이 임베딩을 선언하면 $N(0,1)$ 로부터 초기화된, 훈련가능한 임베딩 파라미터가 생성됩니다. 밑의 경우에는 임베딩 차원이 3인 임베딩 벡터가 10개 생성되어 (10,3) 크기의 파라미터 행렬이 선언됩니다.
# an Embedding module containing 10 tensors of size 3
embedding = nn.Embedding(10, 3)
embedding.weight
주의할 점은 만약 "max_norm" 아규먼트에 값이 주어진다면 Embedding 객체의 forward 메소드에 의해 임베딩 파라미터가 주어진 "max_norm" 크기에 맞게 in-place 방식으로 정규화된다는 것입니다. 기울기 계산을 위해서는 in-place 방식으로 값이 변하면 안되므로 forward 메소드 호출하기 전에 임베딩 파라미터의 기울기를 계산하기 위해서는 파라미터를 다음과 같이 clone 메소드로 복사해서 연산해야 합니다.
n, d, m = 3, 5, 7
embedding = nn.Embedding(n, d, max_norm=True)
W = torch.randn((m, d), requires_grad=True)
idx = torch.tensor([1, 2])
a = embedding.weight.clone() @ W.t() # weight must be cloned for this to be differentiable
b = embedding(idx) @ W.t() # modifies weight in-place
out = (a.unsqueeze(0) + b.unsqueeze(1))
loss = out.sigmoid().prod()
loss.backward()만약 embedding.weight 파라미터를 복사하지 않고 사용한다면 다음과 같이 in-place 오퍼레이션으로 텐서 값이 변경되었다는 런타임 에러가 발생합니다. 물론 위의 경우와 달리 변수 b만 호출하는 forward 메소드만 사용한다면 이러한 작업이 필요 없습니다.

Example
임베딩 파라미터를 선언한 후 forward 메소드를 수행하면 (입력차원, 임베딩차원) 크기를 가진 텐서가 출력됩니다. 이때 forward 메소드의 입력텐서는 임베딩 벡터를 추출할 범주의 인덱스이므로 무조건 정수 타입이 (torch.LongTensor) 들어가야 합니다. 밑의 경우는 forward 메소드에 (2,4) 크기의 텐서가 입력으로 들어가므로 Figure 1과 같이 (2,4,3) 크기의 텐서가 출력됩니다.
from torch import LongTensor, norm
from torch.nn import Embedding
embedding = nn.Embedding(10,3)
sentences = LongTensor([[1,2,4,5],[4,3,2,9]])
embedding(sentences)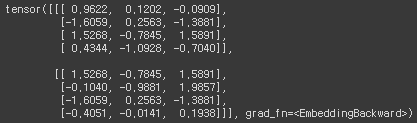
다음과 같이 "max_norm" 아규먼트를 지정하면 forward 메소드가 in-place 방식으로 임베딩 파리미터를 수정합니다. norm 을 이용해 크기를 출력하면 모두 지정한 "max_norm" 아규먼트에 맞게 정규화된 것을 볼 수 있습니다.
from torch import LongTensor, norm
from torch.nn import Embedding
sentences = LongTensor([[1,2,4,5],[4,3,2,9]])
embedding = Embedding(num_embeddings=10, embedding_dim=100, max_norm=1)
for sentence in embedding(sentences):
for word in sentence:
print(norm(word))
또한, "padding_idx" 아규먼트를 지정했을 경우 지정한 인덱스에 대해서는 임베딩 벡터가 0으로 초기화되며 해당 임베딩 벡터는 훈련되지 않습니다.
padding_idx = 0
embedding = nn.Embedding(3, 3, padding_idx=padding_idx)
print(embedding.weight)
마지막으로 임베딩 파라미터는 미리 잘 훈련된 텐서로부터 불러올 수 있습니다. Pytorch 에서는 Embedding 클래스에서 "from_pretrained" 메소드를 지원하는데 이 메소드에 사전훈련된 텐서를 입력으로 넣으면 위와 같이 임베딩을 같이 수행할 수 있습니다.
# FloatTensor containing pretrained weights
weight = torch.FloatTensor([[1, 2.3, 3], [4, 5.1, 6.3]])
embedding = nn.Embedding.from_pretrained(weight)
# Get embeddings for index 1
input = torch.LongTensor([1])
embedding(input)
특히, "from_pretrained" 메소드는 fine-tuning 에서와 같이 "freeze" 라는 불리안 아규먼트를 제공하고 이것이 True면 임베딩 파라미터가 고정되고 업데이트되지 않습니다. (디폴트는 True로 선언되어 있습니다.)

참조
'Machine Learning Models > Pytorch' 카테고리의 다른 글
| Pytorch - backward(retain_graph=True) (2) (1) | 2021.08.01 |
|---|---|
| Pytorch LSTM (0) | 2021.06.26 |
| Pytorch - autograd 정의 (1) | 2021.06.02 |
| Pytorch - gather (0) | 2021.06.01 |
| Pytorch - scatter (3) | 2021.06.01 |

