이전 포스트
Experiment
Image clustering
ImageNet 데이터셋의 비지도학습 벤치마크 데이터셋인 STL10과 MNIST, CIFAR 에 대해서 실험을 수행하며 semi-supervised 방법으로도 실험을 수행합니다. 먼저 clustering이 색깔같은 단순한 특징에 의해 이루어지지 않도록 Sobel filtering 을 수행하며 데이터 augmentation 을 위해 배치 안의 각 이미지별로 $r$ 번 변환을 수행합니다.

Neural networks의 구조로는 CNN의 backbone 으로 ResNet 을 사용하고 CNN의 최종단 $b$에 Figure 2와 같이 여러 개의 출력단 (head)를 붙입니다. 일반적인 IIC 에서는 main head의 출력단 차원을 군집 개수 $k_{gt}$와 같게 하고 overclustering 을 위한 보조 head (auxiliary head) 에는 $k > k_{gt}$를 사용합니다. 특히, auxiliary head를 하나가 아닌 독립적인 $h=5$개만큼 사용하여 (sub-head) 성능을 더 높였다고 합니다. Semi-supervised overclustering 에서는 $k > k_{gt}$인 하나의 출력단이 존재하고 이후 semi-supervised fine-tuning 을 위해서는 기존의 $k > k_{gt}$인 head를 제거하고 $k=k_{gt}$인 head를 추가해 fine-tuning을 진행합니다.

테스트 시에는 auxiliary overclustering 부분은 무시되고 main head 의 출력과 라벨에 대한 hungarian matching 방법으로 성능을 평가합니다. Semi-supervised overclustering 성능 평가시에는 $k > k_{gt}$이므로 $k$를 $k_{gt}$로 매핑하는 함수가 필요하며 강조하지만 라벨은 성능 평가시에만 사용합니다.
결과적으로 기존 baseline 방법에 비해 뛰어난 성능 향상을 이루었습니다. Figure 5는 STL10 데이터셋에 대한 IIC 결과인데 해당 cluster 에 속할 확률이 매우 discriminative 한 것을 볼 수 있습니다. 단 여러 개의 물체가 섞인 데이터셋에 대해서는 잘 동작하지는 않습니다.


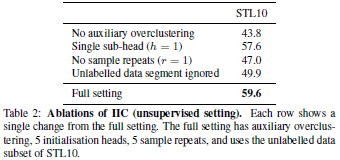
IIC가 제안한 방법들 1) auxiliary clustering 2) multi sub-head 3) $r$ 이 있고/없고에 따른 결과는 Table 2와 같습니다. 특히, auxiliary clustering에 의한 성능 향상이 고무적입니다.
Semi-supervised overclustering 후 fine-tuning 한 결과는 기존 fully-supervised 방법론에 비해 뛰어난 성능을 거두었습니다. 즉, 여기서도 비지도학습에 의거한 feature representation 이 추후 성능향상에 큰 도움이 된다는 사실을 실험적으로 증명한 것인데요, Figure 6을 보면 전체 라벨에서 10%만 사용해도 성능 감소가 거의 없으며 $k$가 증가함에 따라 성능이 증가하는 것을 확인할 수 있습니다.

Segmentation
IIC를 이용한 image segmentation을 위해 COCO-Stuff 데이터를 사용합니다. 여기서 stuff란 이미지 안의 구체적인 물체를 말하며 이미지 전체에서 stuff 비율이 75%가 넘는 데이터셋을 사용해 실험을 수행합니다. 또한 인공위성 데이터셋은 Potsdam 에 대해서는 200x200 사이즈의 이미지들로 구성되어 있습니다. 특히, 각 픽셀 별 분류를 3가지 클래스로 한정한 데이터셋을 각각 COCO-Stuff-3과 Potsdam-3 이라 합니다.
Neural networks 구조로는 CNN $b$에서 1x1 convolution 으로 channel 차원을 조절한 head를 덧붙입니다. Overclustering을 위해서 $k_{gt}$보다 3~5배 큰 $k$를 사용하고 segmentation 은 clustering 이 픽셀 별로 이루어지므로 매우 연산이 커서 $h=1, r=1$을 사용합니다.
결과는 Table 4와 Figure 7과 같습니다. 다른 baseline 방법들은 image clustering 에만 적용되는 방법들이므로 픽셀 별 KMeans를 별도로 수행했습니다. 특히, 배치 안의 모든 이미지의 모든 픽셀에 대해 convolution 을 이용한 병렬적인 최적화를 수행했으므로 segmentation 에 소요되는 훈련 시간이 다른 방법에 비해 더 적게 걸리고 빠르게 수렴합니다.


'Machine Learning Tasks > Clustering' 카테고리의 다른 글
| Clustering - Invariant Information Clustering for Unsupervised Image Classification and Segmentation (1) (0) | 2021.05.16 |
|---|---|
| Clustering - Performance (3), S_Dbw (0) | 2021.05.12 |
| Clustering - Performance (2), Total Sum of Squares (0) | 2021.05.12 |
| Clustering - Performance (1) (0) | 2021.05.11 |
| Clustering - Hungrian Algorithm (2) | 2021.05.11 |



