지난 포스트
[Machine Learning/기타] - Face Recognition - ArcFace (1)
Experiments
Implementation details
ArcFace 저자들은 Table 1에 나와있는 다양한 얼굴 인식 데이터셋에 굉장히 빡세게 실험을 수행했습니다. CASIA, VGGFace2, MS1MV2, DeepGline-Face 데이터셋을 훈련 데이터셋으로 사용했습니다. (MS1MV2 는 MS-Celeb-1M 데이터셋을 자체적으로 정제한 버젼입니다.) SphereFace, CosFace 에서 LFW, YTF, MegaFace 데이터셋에 대해서만 실험을 수행한 것과 달리 기존의 LFW, YTF 에다가 나이 / 포즈에 따른 CPLFW, CALFW 데이터셋에 대해서도 테스트를 수행하였으며 대용량 데이터셋에 대해서는 기존의 MegaFace 에다가 IJB-B, IJB-C, Trillion-Pairs 등의 데이터셋에 대해서도 테스트를 수행합니다.

CosFace 와 마찬가지로 MTCNN 을 이용하여 얼굴의 5개 포인트를 뽑아낸 후 정렬하여 중앙 cropping 을 수행한 얼굴 이미지를 입력으로 사용합니다. Feature 차원은 512, hypersphere 크기 $s$는 64, $m$은 0.5를 사용합니다. 마찬가지로 큰 배치 사이즈에 대해 multi-gpu 를 이용해 훈련하며 초기 learning rate 를 크게 잡은 뒤 감소시키는 전략을 사용합니다. 테스트 시에는 loss 함수를 위한 fully-connected layer 를 제거한 뒤 512 차원의 feature 를 이용해 테스트합니다. 또한, 비디오나 템플릿으로 이루어진 IJB-B/C, YTF 등은 한 비디오나 템플릿의 모든 이미지에서 feature 를 뽑아낸 뒤 평균한 값을 대표 feature 로 사용합니다.
Ablation study on losses
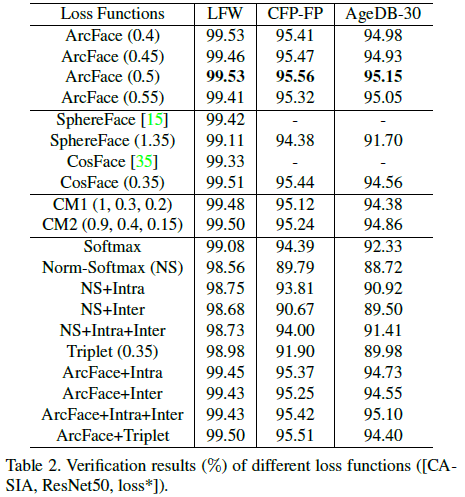
CASIA 데이터셋을 ResNet50 에 훈련한 모델에 대한 face verification (LFW, CFP-FP, AgeDB-30) 전체 결과는 Table 2와 같습니다. ArcFace $m=0.5$ 일때, 성능이 제일 좋았으며 SphereFace 는 arc-cosine 함수를 이용하여 loss 함수를 재구성한 뒤 $m=1.35$를 사용했다고 합니다. 특히, Table 2의 마지막 부분에서는 ArcFace 에다가 inter-loss / intra-loss 등의 loss 함수를 추가한 뒤의 성능을 볼 수 있는데, 성능의 변화가 거의 없는 점으로 미루어보여 ArcFace loss 하나만으로 intra-class compactness / inter-class discrepancy 를 충분히 강제하는 것으로 볼 수 있습니다.
Intra-class compactness / inter-class separation 을 확인하게 위해 feature / weight 벡터 간의 각도를 .Table 3과 같이 분석합니다. ArcFace 의 경우 각도가 14.29 로 Norm Softmax 에 비해 매우 낮으며 Intra-Loss 의 경우 intra-class 각도는 낮지만 inter-class 각도 또한 상대적으로 낮은 것을 볼 수 있고 Inter-Loss 의 경우 inter-class 각도는 높지만 intra-class 각도 또한 높은 것을 볼 수 있습니다. Table 3의 결과로 볼때 ArcFace 만이 intra-class compactness (낮은 각도), inter-class discrepancy (높은 각도) 를 달성합니다.

Evaluation results
먼저 MS1MV2 데이터셋에 ResNet100 으로 훈련시킨 모델에 대한 LFW, YTF, CALFW, CPLFW 데이터셋의 face verification 결과는 Table 4, 5와 같습니다.


MegaFace 데이터셋에 대한 실험은 small dataset (CASIA) / large dataset (MS1MV2) 프로토콜에 대해 수행하고 결과는 Table 6과 같습니다. 참고로 설명하면 face identification 은 주어진 프로브셋 (MegaFace 에서는 FaceScrub 데이터셋) 에 대해 갤러리셋에 들어있는 얼굴을 맞추는 것으로 rank-1 face identification 정확도로 평가합니다. (맞추려고 하는 얼굴이 예상 순위 1등인 것만 참으로 판단하는 것이죠.) Face verification 은 기본적으로 두 이미지가 같은 / 다른 사람인지를 판단하는 것이기 때문에 FAR (False Acceptance Rate = FP / (FP+TN)) 특정 값에 대한 (보통 $10^{-6}$) TAR (True Acceptance Rate = TP / (TP + FN)) 값을 사용합니다.

Table 6를 보면 MegaFace 데이터셋에 대해서도 ArcFace 의 성능이 다른 기존 방법론의 성능을 뛰어 넘습니다. 특히, MegaFace 데이터셋은 라벨이 잘못된 경우가 (같은 클래스 데이터에 다른 사람이 들어 있는 경우) 많은데 이를 정제했을 때 더 높은 성능을 보임을 확인할 수 있습니다. 또한, CosFace 포스트에서도 보았듯이 CosFace 는 MegaFace 실험 시 private 훈련 데이터까지 사용했습니다. 따라서 ArcFace 처럼 MS1MV2, ResNet100 모델의 동일 조건에 대해서 실험했을 때 오히려 논문에 표기된 성능보다 떨어집니다.
Trillion-Pairs 데이터셋은 1.58M개의 Flickr 이미지를 갤러리셋으로 사용하고 274K개의 LFW 데이터셋 사람 이미지를 프로브셋으로 구성됩니다. ArcFace 저자들이 자체적으로 정제한 MS1MV2 데이터셋에 DeepGlint ASIAN 데이터셋을 추가했을 때 성능이 제일 좋았으며, DeepGline-Face 데이터셋의 사람 수가 거의 MS1MV2 데이터셋에 비해 두배 이상 많다는 점을 고려했을 때 놀라운 결과입니다.

참조
'Machine Learning Tasks > Face Recognition' 카테고리의 다른 글
| Face Recognition - ArcFace (1) (0) | 2021.05.23 |
|---|---|
| Face Recognition - CosFace (2) (0) | 2021.05.23 |
| Face Recognition - CosFace (1) (0) | 2021.05.23 |
| Face Recognition - SphereFace (2) (0) | 2021.05.22 |
| Face Recognition - SphereFace (1) (0) | 2021.05.21 |



