유튜브, 넷플리스, 이커머스 등의 플랫폼을 사용하다보면 연관된 영상과 제품이 여러 사용자의 다양한 데이터와 머신러닝 알고리즘에 기반하여 추천됩니다. 내가 이 플랫폼을 처음 사용한다거나 이러한 제품, 영상을 본 적이 없는데도 어떻게 새로운 컨텐츠를 추천할 수 있을까요? 일반적으로 추천 시스템에 (recommender systems) 사용되는 데이터는 Figure 1의 형태처럼 표현할 수 있을겁니다. 행이 유저가 되고 열이 컨텐츠가 되어 특정 인덱스의 행열 값은 유저의 컨텐츠에 대한 rating (score)가 되겠죠. 여기서의 추천 문제는 Figure 1의 데이터에 기반하여 어떤 유저가 어떤 컨텐츠를 얼마나 좋아할까를 예측하는 것입니다.
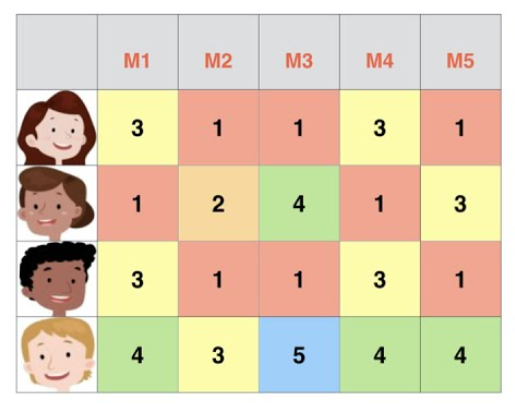
이러한 류의 문제는 기존의 행렬분해법 (Matrix Factorization) 을 이용해 접근했습니다. 즉, 각 유저와 아이템을 특정 차원을 가지는 잠재벡터로 모델링하고 Figure 1의 4x5 행렬을 Figure 2와 같이 유저에 대한 4x2, 아이템에 대한 5x2 크기의 행렬의 곱으로 나타내는 것이죠. (여기서 2는 잠재벡터의 차원입니다.) 각 행렬을 이루는 벡터의 내적을 통해 특정 유저의 특정 아이템에 대한 레이팅을 얻을 수 있고 분해된 행렬은 SVD (Singular Value Deposition) 이나 경사하강법을 이용해 구할 수 있습니다. 하지만 행렬분해법은 행렬 속성 간의 인수분해에 기반해서 전체 행렬을 예측해야 하기 때문에 유저, 아이템 수가 많아질수록 연산량이 기하급수적으로 커집니다. 또한 이러한 행렬 형태는 영화의 장르, 나이, 성별과 같은 추가적인 feature를 추가하기가 굉장히 까다롭습니다.

다르게 접근해서 결국 우리가 (유저, 아이템) 입력으로 레이팅이라는 출력을 예측하는 것이라면, Figure 3과 같이 유저, 아이템을 카테고리 형 데이터를 one-hot 인코딩하여 레이팅에 대한 회귀분석으로 표현할 수 있습니다. 그렇다면 SVM, XGBOOST 등과 같은 머신러닝 모델에 대해 단순히 학습하면 좋은 에측을 할 수 있지 않을까요? 하지만 Figure 3과 같은 추천 데이터 형태는 치명적으로 대부분의 셀의 값이 0으로 된 sparse 행렬입니다. 이러한 상황에서는 대부분의 데이터가 0으로 이루어져 있기 때문에 의미있는 파라미터를 학습할 수 없고 각 feature 간의 상호관계를 모델링할 수 없습니다.

이번 포스트에서는 굉장히 sparse 한 (유저, 아이템)의 입력 feature 상황에서도 각 feature의 잠재벡터를 학습하고 이를 기반으로 feature 간의 상호관계까지 모델링하여 레이팅을 예측하는 Factorization Machine (FM)에 대해 살펴보도록 하겠습니다.
Factorization machine
먼저 Figure 3의 상황에 대해서 간단한 선형회귀 모델로 접근한다면 유저 필드가 3차원, 아이템 필드가 4차원이라면 총 7차원의 feature에 대해 파라미터 $w$를 학습하면 될 겁니다. 하지만 이런 경우는 각 feature 사이의 상호관계가 무시되므로 Equation 1과 같이 polynomial 회귀로 표현할 수 있습니다. 이때 $x_i$는 7차원 feature 값 중 하나의 차원으로 예를 들어 유저필드의 벡터가 (1,0,0)이라면 1,0,0은 각각 $x_1, x_2, x_3$이 됩니다. 하지만 이 방법의 문제는 데이터가 매우 sparse 하다면 $x_i=x_j=0$인 경우에 대해 $w_{ij}$를 학습할 수가 없다는 점입니다. 또한, 입력하는 feature가 많아질수록 계산해야하는 $w_{ij}$가 많아지고 이를 위해 매우 많은 데이터가 필요합니다.

Example
Figure 4와 같은 데이터를 가정하겠습니다. 파란색은 유저, 주황색은 영화 아이템, 노란색은 해당 유저가 기존에 평가한 영화 점수, 초록색은 시간, 갈색은 직전에 평가한 영화를 나타내고 $y$는 주황색 영화 아이템에 대한 유저의 평가입니다. 유저와 영화는 범주형 변수이므로 one-hot 인코딩 되어 있습니다. 여기서 문제는 Figure 4에 존재하지 않는 feature 조합에 대해 (유저 A의 영화 ST) 레이팅을 예측하는 것이죠.


Model
Factorization Machine (FM)은 Equation 2와 같이 $y$에 대한 회귀식을 표현합니다. 이때, $w_0\in R, w\in R^n, V\in R^{n\times k}$로 $n$은 전체 feature 개수, $k$는 각 feature를 나타낼 잠재벡터의 차원입니다. 위의 Polynomial을 이용한 Equation 2와의 차이는 FM에서는 feature 사이의 상호관계를 나타내기 위해 $w_{ij}$를 직접적으로 학습하는 것이 아니라 $W\in R^{n\times n}$을 $V\in R^{n\times k}$를 이용해 분해하여 (factorize) $V$를 학습하는 것이죠. 따라서 $<v_i, v_j>$는 Equation 3과 같이 정의됩니다.
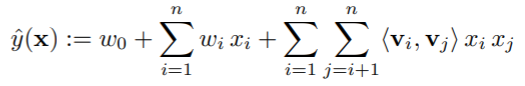

일반적으로 positive definite matrix $W$에 대해서 충분히 큰 $k$에 대해 $W=V\cdot V^T$를 만족하는 $V$가 존재한다고 알려져있고 이는 feature 사이의 상호관계를 나타내는 행렬 $W$를 각 feature의 잠재벡터 $v_i$의 내적으로 표현할 수 있다는 것이죠. 추천 시스템에서는 데이터가 매우 sparse 하므로 더 좋은 일반화를 위해 $k$를 어느 정도 작은 값을 잡습니다.
특히, sparse 데이터 상황에서 $w_{ij}$를 각 케이스 별로 독립적으로 학습하기가 힘든 반면에 $W$를 $V$로 분해함으로써 각 feature의 잠재벡터를 학습하므로 독립성을 깨고 특정한 상호관계를 나타내는 데이터로부터 실제 데이터가 존재하지 않는 상호관계를 예측할 수 있습니다. 예를 들어 Figure 4를 보면 (유저 A, 영화 ST) 상호관계를 예측한다고 했을 때 이러한 경우를 나타내는 데이터가 존재하지 않으므로 $w_{A, ST}=0$이 됩니다. $W$를 예측할 경우 상호관계가 존재하지 않게 나온다는 것이죠. 하지만 factorize를 통해 $v_{A}, v_{ST}$로 표현한다면 상호관계를 예측할 수 있습니다. 먼저 유저 B, C는 영화 SW에 대해 비슷한 예측값을 내므로 $<v_B, v_{SW}>$, $<v_C, v_{SW}>$ 값이 비슷할 것입니다. 유저 A와 C는 영화 TI, SW에 대해 예측값이 상반되므로 $v_A, v_C$는 서로 비슷하지 않겟죠. 다음으로 영화 SW, ST의 feature 벡터는 유저 B가 둘에 대해 높은 점수를 주었으므로 비슷할 것입니다. 이러한 방법으로 유저 A, 영화 ST 경우에 대해서 실제 데이터가 존재하지 않더라도 각 feature의 잠재벡터를 다른 상호관계로부터 학습하여 예측할 수 있다는 점입니다. 이 경우에 대해서는 $<v_A, v_{SW}>$와 $<v_A, v_{ST}>$가 비슷하다고 추측할 수 있겠죠.
Equation 2를 수식 그대로 두 번의 for 문을 사용한다면 $O(k\cdot n^2)$의 시간복잡도가 소요됩니다. 하지만 Equation 4와 같은 reformulation 으로 $O(k\cdot n)$으로 시간복잡도를 선형으로 줄일 수 있습니다.
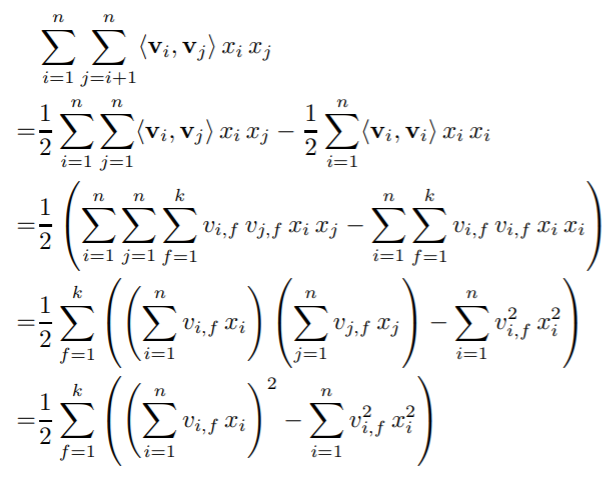
FM의 학습으로는 SGD (Stochastic Gradient Descent) 방법을 사용해서 구할 수 있고 Equation 5의 기울기는 각각 $O(1)$ 시간복잡도가 소요되고 파라미터 업데이트를 위한 전체 시간복잡도는 $O(kn)$이 소요됩니다.
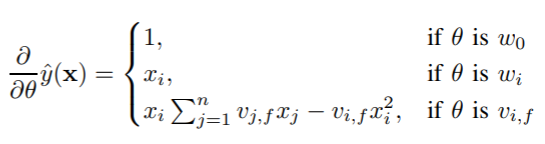
FM은 일반적인 predictor로 least square를 이용한 회귀, 0, 1 분류, 점수 랭킹 문제에 제너럴하게 사용될 수 있으며 다양한 loss 함수를 적용해 사용할 수 있습니다. 또한 과적합을 방지하기 위해 $L2$ 정규화와 일반적으로 같이 사용합니다. 정리하면 FM은 매우 sparse한 데이터 상황에 대해서도 각 feature 사이의 상호관계를 추정할 수 있고 Equation 4로 시간복잡도가 선형이 되고 Equation 5로 기울기가 잘 정의되어 있기 때문에 feasibility가 높고 SGD로 쉽게 최적화가 가능합니다.
'Machine Learning Tasks > Recommender Systems' 카테고리의 다른 글
| RecSys - DeepFM (0) | 2021.07.15 |
|---|---|
| RecSys - Field-aware Factorization Machines (0) | 2021.06.23 |
| RecSys - Factorization Machines (3), Pytorch 구현 (2) | 2021.06.23 |
| ResSys - Factorization Machines (2) (0) | 2021.06.22 |



