RecSys - Factorization Machines (1)
ResSys - Factorization Machines (2)
이번 포스트에서는 Factorization Machines (FM)을 Pytorch 프레임워크로 구현해보려 합니다. 먼저 추천 시스템에서 자주 쓰이는 벤치마크 데이터셋 MovieLens 20M을 다운받습니다. MovieLens 데이터셋은 다양한 종류가 있으며 여러 유저의 여러 영화에 대한 평가와 장르, 태그와 같은 메타 데이터가 csv 파일로 존재합니다. 그중 MovieLens 20M 데이터셋은 13만여명 유저의 3만여개의 영화에 대한 2백만개의 5-star 레이팅으로 구성되어 있습니다. (Figure 1, ratings.csv)
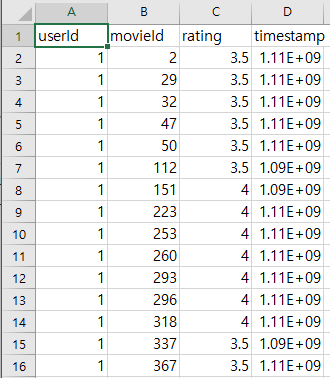
Load datasets
먼저 Pytorch의 Dataset api를 이용해 Figure 1 데이터를 불러오는 코드를 구현합니다. 'userId', 'movieId' 컬럼이 feature가 되고 'rating' 컬럼이 예측할 타겟이 됩니다. 이진분류 형태로 훈련할 것이므로 (BCE, Binary Cross Entropy) 'rating'이 3점 미만은 0, 3점 이상은 1로 바꿉니다. 또한 각 'Id'가 1부터 시작하므로 0부터 시작하는 것으로 바꾸기 위해 1을 빼주고 정수 타입으로 변환합니다.
class MovieLens20MDataset(torch.utils.data.Dataset):
"""
MovieLens 20M Dataset
Data preparation
treat samples with a rating less than 3 as negative samples
:param dataset_path: MovieLens dataset path
Reference:
https://grouplens.org/datasets/movielens
"""
def __init__(self, dataset_path, sep=',', engine='c', header='infer'):
data = pd.read_csv(dataset_path, sep=sep, engine=engine, header=header).to_numpy()[:, :3]
self.items = data[:, :2].astype(np.int) - 1 # -1 because ID begins from 1
self.targets = self.__preprocess_target(data[:, 2]).astype(np.float32)
self.field_dims = np.max(self.items, axis=0) + 1
self.user_field_idx = np.array((0, ), dtype=np.long)
self.item_field_idx = np.array((1,), dtype=np.long)
def __len__(self):
return self.targets.shape[0]
def __getitem__(self, index):
return self.items[index], self.targets[index]
def __preprocess_target(self, target):
target[target <= 3] = 0
target[target > 3] = 1
return target- self.field_dims 이라는 변수에 'userID', 'movieId' 컬럼의 최대값을 담습니다. 따라서 __getitem__ 메소드를 통해 출력되는 feature는 [userId 번호, movieId 번호]가 되며 이 값으로 임베딩 파라미터를 인덱싱하여 각 feature의 잠재벡터 (임베딩 벡터)를 얻습니다.
이후에는 전체 2백만여개 데이터를 train/val/test 데이터셋으로 랜덤하게 나누어주고 DataLoader api를 이용해 배치 단위로 부르는 코드를 작성합니다. Feature 수가 2개이므로 1000 이상의 배치 사이즈를 잡아도 무방합니다. 정의한 DataLoader를 반복가능하게 호출할 때마다 [배치 사이즈, 2] 크기의 텐서가 생성됩니다.
dataset = MovieLens20MDataset(dataset_path=path)
train_length = int(len(dataset) * 0.8)
valid_length = int(len(dataset) * 0.1)
test_length = len(dataset) - train_length - valid_length
train_dataset, valid_dataset, test_dataset = torch.utils.data.random_split(
dataset, (train_length, valid_length, test_length))
batch_size=1024
train_data_loader = DataLoader(train_dataset, batch_size=batch_size, num_workers=8)
valid_data_loader = DataLoader(valid_dataset, batch_size=batch_size, num_workers=8)
test_data_loader = DataLoader(test_dataset, batch_size=batch_size, num_workers=8)- torch.utils.data.random_split 메소드를 사용해 기존의 dataset을 분해하면 Subset dataset이 생성되고 'indices' 메소드로 전체 dataset의 어떤 인덱스로 Subset이 구성되었는지 알 수 있습니다. Subset을 만들 인덱스만 생성하기 때문에 기존 dataset의 속성에는 접근할 수 없습니다.
Model
먼저 Equation 1에서 선형 결합 부분을 정의합니다. 입력 텐서가 [배치 사이즈, 2] 크기이고 dim=1 에는 'userId', 'MovieId' 번호가 담겨져 있으므로 이를 위에서 계산한 "self.field_dims"에 맞게 전체 feature에 대한 위치를 계산합니다. 에를 들어 userId의 필드차원이 10000이고 MovieId가 3이라면 MovieId의 전체 feature에 대한 위치는 10003이 되는 것이죠. 이후에 Embedding 클래스로 선언한 임베딩 파라미터를 입력 텐서에 대해 forward 하면 [배치 사이즈, 2, 임베딩 차원=1] 이 되고 이를 feature 차원에 대해 합해줍니다.
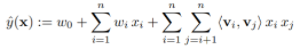
class FeaturesLinear(torch.nn.Module):
def __init__(self, field_dims, output_dim=1):
super().__init__()
self.fc = torch.nn.Embedding(sum(field_dims), output_dim)
self.bias = torch.nn.Parameter(torch.zeros((output_dim,)))
self.offsets = np.array((0, *np.cumsum(field_dims)[:-1]), dtype=np.long)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
x = x + x.new_tensor(self.offsets).unsqueeze(0)
return torch.sum(self.fc(x), dim=1) + self.bias
test_fn = FeaturesLinear(field_dims=dataset.field_dims)
test_fn(next(iter(train_data_loader))[0]).shape- Equation 1의 $w_i$는 각 feature에 대한 가중치이므로 임베딩 차원을 1로 설정합니다.
- self.bias는 Equation 1의 $w_0$와 같고 1차원 텐서입니다.
이제 Equation 1에서 factorization을 통해 얻은 $v_i$를 구현해줄 차례입니다. 위와 거의 비슷하나 임베딩 차원 $k$를 16으로 설정합니다. forward 메소드에 [배치 사이즈, 2] 입력이 들어간다면 [배치 사이즈, 2, 임베딩 차원=16] 텐서가 출력됩니다.
class FeaturesEmbedding(torch.nn.Module):
def __init__(self, field_dims, embed_dim=16):
super().__init__()
self.embedding = torch.nn.Embedding(sum(field_dims), embed_dim)
self.offsets = np.array((0, *np.cumsum(field_dims)[:-1]), dtype=np.long)
torch.nn.init.xavier_uniform_(self.embedding.weight.data)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
x = x + x.new_tensor(self.offsets).unsqueeze(0)
return self.embedding(x)마지막으로 Equation 1의 오른쪽 항을 구현합니다. 지난 포스트에서 봤듯이 FM 에서는 이 항을 brute force로 $O(kn^2)$ 시간복잡도로 계산하지 않고 Equation 2와 같이 reformulation 하여 $O(kn)$ 시간복잡도로 구합니다.

따라서 [배치 사이즈, feature 인덱스, 임베딩 차원] 크기 텐서가 입력으로 들어올 경우 square-of-sum과 sum-of-square을 feature 인덱스 차원에 대해 계산하여 Equation 2대로 계산합니다.
class FactorizationMachine(torch.nn.Module):
def __init__(self, reduce_sum=True):
super().__init__()
self.reduce_sum = reduce_sum
def forward(self, x):
"""
:param x: Float tensor of size ``(batch_size, num_fields, embed_dim)``
"""
square_of_sum = torch.sum(x, dim=1) ** 2
sum_of_square = torch.sum(x ** 2, dim=1)
ix = square_of_sum - sum_of_square
if self.reduce_sum:
ix = torch.sum(ix, dim=1, keepdim=True)
return 0.5 * ix마지막으로 위 3개의 모듈을 합친 최종적인 모델을 다음과 같이 구현합니다. 레이팅 0, 1을 예측하는 이진분류 문제이고 Equation 1의 결과는 스칼라 값이므로 마지막 차원을 squeeze 메소드를 통해 없앤뒤 sigmoid 함수를 붙입니다.
class FactorizationMachineModel(torch.nn.Module):
"""
A pytorch implementation of Factorization Machine.
Reference:
S Rendle, Factorization Machines, 2010.
"""
def __init__(self, field_dims, embed_dim):
super().__init__()
self.embedding = FeaturesEmbedding(field_dims, embed_dim)
self.linear = FeaturesLinear(field_dims)
self.fm = FactorizationMachine(reduce_sum=True)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
x = self.linear(x) + self.fm(self.embedding(x))
return torch.sigmoid(x.squeeze(1))
참조
'Machine Learning Tasks > Recommender Systems' 카테고리의 다른 글
| RecSys - DeepFM (0) | 2021.07.15 |
|---|---|
| RecSys - Field-aware Factorization Machines (0) | 2021.06.23 |
| ResSys - Factorization Machines (2) (0) | 2021.06.22 |
| RecSys - Factorization Machines (1) (4) | 2021.06.22 |



