Pytorch - DistributedDataParallel (1) - 개요
Pytorch DDP (torch.nn.parallel.DistributedDataParallel) 함수는 어떤 방식으로 동작할까요? 먼저 각 process 별로 torch.nn.Linear 함수를 이용한 간단한 선형모델을 한 번의 forward/backward pass를 거치는 간단한 예제를 살펴보겠습니다.
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
# create default process group
dist.init_process_group(backend="gloo", rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
def main():
world_size = 2
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)- 구조를 보면 main 함수 안에 torch.multiprocessing.spawn 함수를 통해 example 함수를 실행시키는 것을 볼 수 있습니다. 파이썬의 내장 multiprocessing 라이브러리 대신 이를 torchtorch의 multiprocessing 라이브러리를 이용하며, world size 만큼의 processing을 launching 합니다.
- 이때 example 함수의 argument인 "rank"와 "world_size"는 각각 spawn 함수의 "args"와 "nprocs" 매개변수를 통해 전달되고 "nprocs" 매개변수가 launching할 프로세수 개수를 나타냅니다. 마지막으로 "join=True"는 모든 프로세스들이 종료되기를 기다리는 blocking 동작을 뜻합니다. 이 구조는 일반적인 DDP 구현체에 거의 동일하게 적용됩니다.
Overall process
1. Prerequisite
제일 처음으로 전체 프로세스 그룹에서 tensor 간 이동 및 계산과 같은 collective communtation을 지원하는 c10d 라이브러리 백엔드를 호출해야하며 example 안의 "dist.init_process_group" 함수가 해당됩니다. Pytorch에서는 nccl/gloo/mpi 백엔드를 지원하는데 일반적으로 nccl이 사용됩니다. (예제에서는 gloo가 사용되었지만 보통 gpu를 이용한 딥러닝 분산 훈련에서는 nccl 백엔드가 성능 및 속도가 더 좋습니다.) 이 과정을 통해 각 gpu 별로 spawned process가 프로세스 그룹에 등록되고 이를 통해 broadcast/all-reduce 등의 collective communication이 가능해집니다.
참고로 collective communication의 broadcast는 Figure 1의 왼쪽 그림처럼 rank 0 (master rank)의 값을 다른 rank의 프로세스로 퍼뜨리는 동작이고 all-reduce는 모든 rank의 해당 파라미터의 값을 더해 각 rank 마다 같은 값을 가지도록 하는 동작을 말합니다.

2. Construction
torch.nn.parallel.DistributedDataParallel 함수를 통해 각 프로세스에서 생성된 모델을 DDP 모델로 사용할 수 있게 하는 과정으로 example 안의 "DDP(model, device_id=[rank])" 구문이 이 역할을 담당합니다. 이 과정을 통해 master rank인 rank 0의 모델 파라미터를 다른 rank로 broadcast 함으로써 각 프로세스의 모델 복사본이 같은 상태에서 시작할 수 있게 합니다. 물론 이러한 broadcast 과정은 1번 prerequisite 과정에서 프로세스 간 collective communication을 해주었기 때문에 가능합니다.
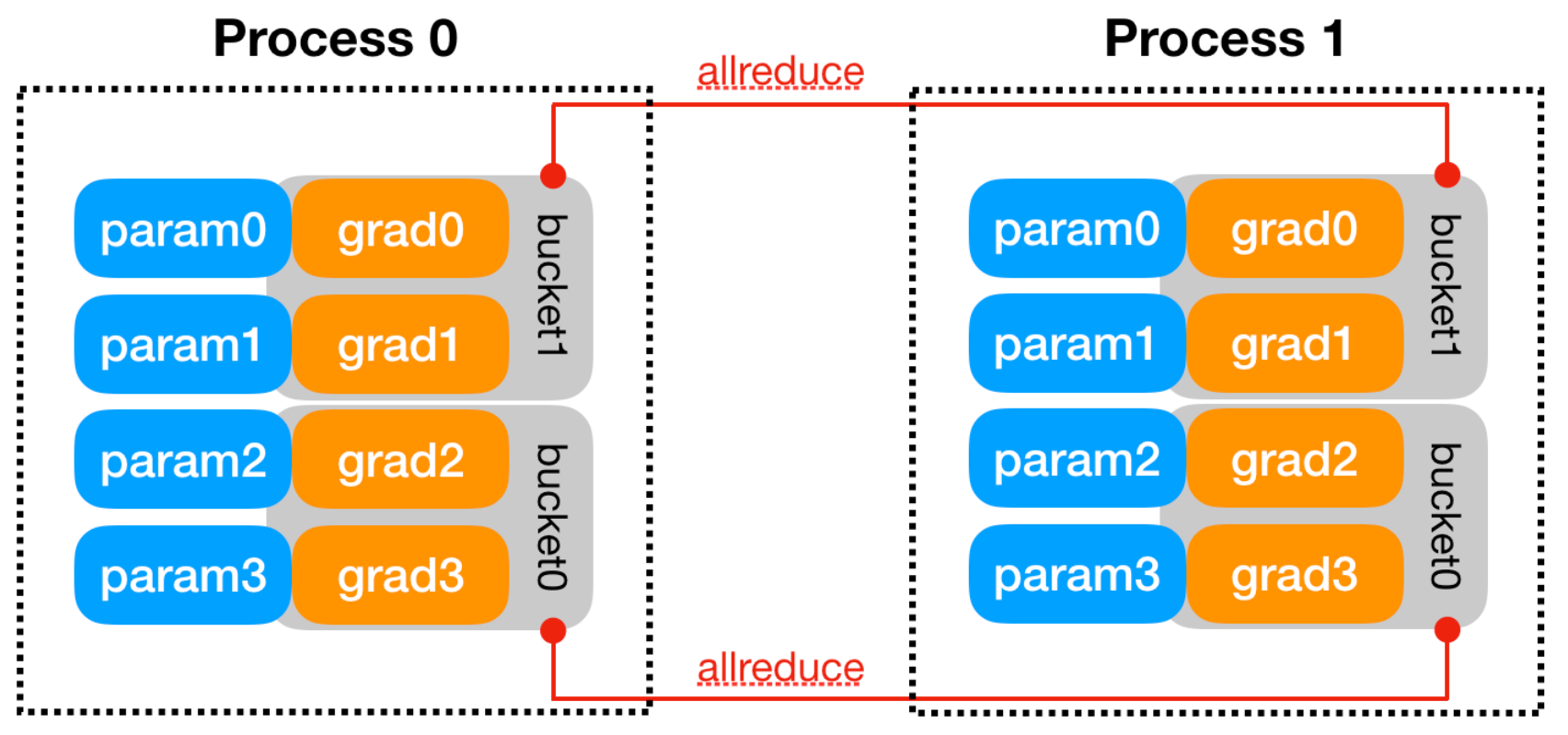
이후 각 rank에서 생성된 DDP 모델은 backward pass에서 계산된 gradient의 동기화를 위한 Reducer 객체를 생성하고 Reducer는 효율적인 collective communication을 위해 parameter gradients의 묶음인 bucket을 생성합니다. Figure 2처럼 각 gpu에서 계산된 gradient가 합산되는 all-reduce 과정이 bucket 단위로 수행되는 것이죠. "DDP(model)" 선언을 할 때 별도의 매개변수 (find_unsued_parameters=True)가 세팅되지 않는 한 bucket size나 parameter size에 따라 parameter gradients 매핑이 자동으로 결정됩니다. 또한, 각 파라미터 별로 gradient hook를 등록해서 backward pass에서 해당 파라미터의 gradient가 계산되었을 시 발동되도록 합니다.
3. Forward pass
일반적인 neural networks의 forward pass 입니다. 각 프로세스 별로 개별적인 데이터를 받아 neural networks의 출력과 loss를 계산합니다.
4. Backward pass
각 프로세스 별로 loss가 계산이 되면 2번 construction 단계에서 등록한 gradient hook를 이용해 각 프로세스의 해당되는 파라미터 별 gradient를 all-reduce 과정을 통해 합하고 동기화합니다. 각 파라미터의 gradient가 계산이 되면 hook가 발동되고 한 bucket에 속한 gradient가 모두 계산이 되면 완료된 bucket 별로 all-reduce 과정을 수행해 각 프로세스에서 계산된 해당 bucket에 속한 파라미터의 gradient를 비동기적으로 합산합니다. 대신 모든 bucket의 gradient 계산이 완료되면 동기화를 위해 모든 bucket의 all-reduce 과정이 완료되기까지 block을 수행합니다. 이 과정이 끝나면 각 파라미터의 평균 gradients (all-reduce를 통해 계산한 gradients)가 param.grad에 등록됩니다. 따라서 이러한 gradient 동기화 과정을 통해 모든 프로세스의 파라미터 별 gradient는 (param.grad) 모두 같게 되겠죠.
5. Optimizing step
각 프로세스 별로 4번 과정에서 계산한 기울기를 통해 모델 파라미터를 업데이트합니다. 2번 과정부터 각 프로세스의 모든 모델이 같은 상태에서 시작하면서 매 iteration마다 같은 기울기를 가지고 있으므로 동기화가 된 상태여야겠죠.
Implementation
DDP의 구현체는 크게 1) collective communication을 위한 nccl, gloo 등의 프로세스 그룹을 생성하는 api를 구현한 ProcessGroup.hpp, 2) backward pass의 gradient 동기화를 구현한 reducer.h, 3) broadcast, all-reduce 등의 collective communication을 구현한 comm.h, 4) DDP 파이썬 엔트리 포인트를 정의하고 초기화 및 forward 함수를 구현한 distributed.py 파일로 구성되어 있습니다. 특히, reducer.h 에는 2번 과정에서의 Reducer 및 gradient hook가 구현되어 있습니다.

참조
'Machine Learning Models > Pytorch' 카테고리의 다른 글
| Pytorch 텐서 복사 - clone, detach 차이 (0) | 2023.05.04 |
|---|---|
| Pytorch - DistributedDataParallel (1) - 개요 (0) | 2021.10.23 |
| Pytorch - DataParallel (0) | 2021.10.22 |
| Pytorch - ModuleList vs List (0) | 2021.08.09 |
| Pytorch - backward(retain_graph=True) (2) (1) | 2021.08.01 |


