YOLO와 같은 딥러닝을 이용한 object detection 은 입력 이미지를 몇 개의 grid 구역으로 나누고 각 grid 별 bounding box 를 제안하여 각 bound box의 위치, 크기, 물체가 담길 확률을 계산하는 방식으로 이루어집니다. Figure 1을 보면 입력 이미지를 7x7, 총 49개의 격자로 구분하고 각 격자 별로 두 개의 bounding box를 제안하고 각 bounding box 마다 1) bounding box의 중심 (x, y), 2) bounding box의 크기 (w, h), 3) bounding box 에 물체가 있을 확률을 예측합니다.

7x7x30 의 출력 텐서에서 2개의 bounding box 에 대한 예측 10개를 제외한 나머지 20개는 물체가 있을 때의 물체의 클래스를 예측하는 텐서로 ($p(obj_i | obj in box)$, 클래스의 종류는 20개라 가정합니다.) 이것과 각 bounding box 마다 존재하는 물체가 있을 확률 $p(obj in box)$ 을 곱해 해당 격자의 bounding box 의 20개 클래스에 대한 최종 class score 를 유도하고 이를 모든 격자에 대해 반복하면 입력 이미지에 존재하는 98 (49x2) 개의 bounding box 에 대한 class score를 Figure 2와 같이 유도할 수 있습니다.

이 상태에서 각 bounding box 의 score 가 일정 임계치 이상이면 참이라고 판단하는 경우의 문제는 Figure 3과 같이 같은 물체에 대하여 많은 bounding box 가 잡힐 수가 있다는 점입니다. 따라서 object detection 에서는 한 객체에 대해 가장 신뢰도가 높은 하나의 bounding box 만 남기고 그 객체와 관련된 나머지 bounding box 를 없애는 후처리 과정이 (post-precessing) 필요한데, 이때 사용하는 알고리즘이 바로 NMS (Non-maximum Suppression) 입니다.

Non-maximum suppression
주어진 bounding box 의 집합 $B$, $B$의 class score $S$, overlap 임계치 $N$이 주어졌을 때, NMS 는 다음과 같은 방식으로 동작합니다.
1) 해당 클래스에 대해 최종적으로 남길 bounding box 를 담을 리스트 $D$를 생성하고 $B$ 중에서 class score 가 가장 높은 bounding box 를 선택하고 $B$에서 삭제하고 $D$에 추가합니다. 또한, class score 가 너무 낮은 (0.2 기준) bounding box 또한 $B$에서 제거합니다.
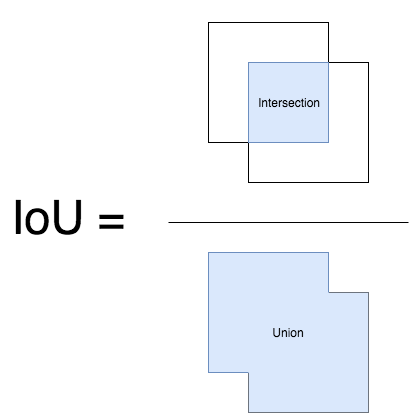
2) $D$에 추가된 class score 가 가장 높은 bounding box 와 $B$에 담긴 bounding box 와의 IOU (Intersection Over Union) 을 계산합니다. IOU는 두 개의 bounding box 가 얼마나 겹쳐져 있는지 나타내는 지표로 Figure 4와 같이 계산합니다. IOU 가 주어진 임계치 $N$보다 크다면 $B$에서 제거합니다.
3) 2번 과정을 수행하고 $B$에 남은 bounding box 중 가장 큰 class score 를 가진 bounding box 를 $B$에서 제거하고 $D$에 추가해 2번 과정을 반복합니다. 이것은 $B$에 bounding box 가 남지 않을 때까지 반복합니다.
따라서 NMS 후처리 과정을 수행하면 Figure 5와 같이 차량을 선택하는 여러 개의 bounding box 중 가장 적합한 것만 남길 수 있습니다.

Problems
NMS 는 하나의 임계치 $N$에 대해서 수행하기 때문에 $N$을 어떻게 선택하느냐에 따라 성능 평가 결과가 달라집니다. Class score 가 가장 높지만 물체와의 IOU가 낮은 bounding box $M$과 물체와의 IOU가 0.7로 높지만 class score 가 $M$보다는 낮은 bounding box $b_i$가 있을 경우에 $N=0.3$ 정도로 낮고 참으로 선택하는 임계치가 $O=0.7$로 높다면 $b_i$는 참이어야 하지만 $N$이 낮아 NMS 에 의해 없어질 확률이 높아지므로 최종 성능평가가 떨어지는 원인이 됩니다. 반대로 $N=0.7$ 로 높고 $O$가 상대적으로 낮을 경우 많은 false positive 가 생성되게 됩니다. 물론 true positive 도 많이 생성되겠지만 bounding box 수에 비해 물체의 수가 현격히 적으므로 최종 average precision 이 낮아지게 하는 원인이 됩니다.
정리하면 Figure 6과 같이 같은 클래스의 물체가 겹쳐 있을 경우 각 물체에 대해 bounding box 를 잡아야 함에도 불구하고 NMS 에 의해 작은 score 를 가진 bounding box 가 무시된다는 점입니다. 특히, 각 물체가 지나치게 겹쳐있을 때 이러한 현상이 심해집니다. Figure 6의 경우 초록색 bounding box class score 가 0.8로 높음에도 불구하고 빨간색 bounding box 에 의해 없어지게 되겠죠.

이는 NMS가 Equation 1과 같이 IOU가 $N$을 넘으면 score 를 무조건 0으로 만들어버리는 알고리즘적 특성에 의해 발생합니다. 따라서 이렇게 0으로 만들어버리지 않고 IOU에 비례해서 class score 를 낮추는 Soft-NMS 알고리즘이 제안되었습니다.

Soft-NMS
NMS 의 문제를 개선하기 위해서는 1) false positive 를 많이 발생시키지 않아야 하고, 2) $N$이 낮고 $O$가 높은 경우처럼 참인 bounding box 가 사라지는 경우를 없애야 합니다. 따라서 soft-NMS 에서는 $M$과 나머지 bounding box $b_i$에 대해 Equation 2와 같은 Gaussian 기반의 scoring 방식을 제안합니다.

Equation 1과 같이 특정 IOU 임계치 $N$을 넘는 bounding box 에만 scoring을 하는 것이 아니라 Equation 2는 전체 bounding box 에 대해 연속적으로 scoring 하는 것으로 $M$과 많이 겹친다면 score 가 많이 낮아지게 되고 $M$과 겹치지 않는다면 원래 score 가 거의 그대로 유지됩니다. 최종적으로 Figure 7과 같이 기존 NMS 가 soft-NMS 로 대체됩니다. 이 간단한 방식으로 기존 PASCAL VOC 2007, MS-COCO에 대한 mAP가 1% 이상 상승했다고 하며, 기존 NMS의 scoring 방식만 대체한 것이기 때문에 계산량이 더 들거나 하는 오버헤드가 발생하지 않습니다. ($N$개의 bounding box 에 대해 $O(N^2)$의 시간복잡도가 소요됩니다.) 또한, 매 iteration 마다 class score 가 너무 낮은 경우는 없애버리면 되기 때문에 계산 속도를 더 상승시킬 수 있습니다.

참조
'Machine Learning Tasks > Object Detection' 카테고리의 다른 글
| Object Detection - YOLO v3 Pytorch 구현 (1) (0) | 2021.06.11 |
|---|---|
| Object Detection - SSD (Single Shot MultiBox Detector) (0) | 2021.06.07 |
| Object Detection - DIoU, CIoU (0) | 2021.06.07 |
| Object Detection - YOLO v3 (2) | 2021.06.03 |
| Object Detection - YOLO v2 (0) | 2021.06.01 |



