이번 포스트에서는 YOLO (You Only Look Once) 후속작 YOLO v2 에 대해서 다뤄보도록 하겠습니다.
Better
YOLO 가 다른 detection 모듈에 비해 대표적으로 안좋은 점은 적은 수의 bounding box 로 인해 재현율이 (recall) 낮다는 점입니다. 특히, 컴퓨터 비젼에서는 점점 더 깊고 큰 neural networks 를 사용하는 추세이지만 object detection 은 정확하고 충분히 빨라야하기 때문에 YOLO v2 에서는 모델을 더 크게 구성하는 대신 모델의 구성요소를 바꾸어 성능을 향상시킵니다.
Batch normalization
먼저 모든 convolution layer 에 batch normalization 을 적용합니다. 이를 통해 2% 정도의 mAP 향상을 이루어냅니다. 또한, batch normalization 은 정규화 효과도 가지고 있으므로 기존 모델에서 dropout 을 제거합니다.
High resolution classifier
대부분의 detection 방법은 ImageNet 데이터셋에 대해 사전학습을 수행한 이후에 detection 데이터셋을 가지고 fine-tuning 하는 방법으로 이루어지는데 기존 YOLO에서 사용하는 모델은 VGG16 기반으로 224x224 크기의 이미지에 대해 훈련되고 detection 시에는 448x448 크기로 해상도가 확대됩니다. (Figure 1) 이는 neural networks 가 새로운 해상도에 적응해야 하는 문제가 있는데요, YOLO v2 에서는 ImageNet 데이터셋을 448x448 로 확대하여 10 epochs 동안 미리 훈련시킨 이후에 detection 데이터셋에 대해 fine-tuning 을 수행합니다. 이를 통해 mAP 가 4% 정도 향상되었다고 합니다.

Convolution with anchor boxes
기존 YOLO 에서는 Figure 1과 같이 각 그리드의 bounding box 좌표를 convolution layer 로부터 추출한 feature 에 대해 fully-connected layer 를 적용하여 예측합니다. 이에 반해 Faster R-CNN 과 같은 region proposal network (RPN) 계열은 convolution layer 만을 사용하여 최종 feature map 의 각 픽셀 별로 앵커 박스를 설정하고 이에 대한 offset 과 confidence 를 예측합니다. YOLO 와 같이 좌표를 직접 학습하는 것이 아니라 미리 정의된 앵커 박스에 대한 비율을 예측하는 것이 학습이 더 쉽기 때문에 YOLO v2 에서는 RPN 방식을 사용합니다.
따라서 앵커 박스를 5개로 미리 설정하고 fully-connected layer 를 사용하지 않습니다. 또한, Figure 1에서 feature map 크기를 늘리기 위해 max-pooling layer 를 하나 삭제하고 최종 feature map 크기가 13x13 같이 홀수로 만들기 위해 입력 이미지를 416x416 크기로 잡습니다. (홀수로 잡는 이유는 보통 큰 물체는 이미지의 가운데를 점유하므로 한 가운데의 하나의 픽셀이 이를 예측하도록 하는 것이 좋기 때문입니다)
또한, RPN 방식으로 변환하면서 기존 YOLO 에서는 하나의 그리드에서 클래스 분류 확률을 공유했다면 YOLO v2 에서는 각 앵커 박스가 클래스 분류 확률을 개별적으로 지닙니다. YOLO 와 마찬가지로 confidence 는 예측한 박스와 ground truth 의 IOU 를 예측하고 클래스 분류 확률은 물체가 존재할 때의 해당 물체의 클래스 확률을 예측합니다. 이러한 방식으로 기존 98개의 bounding box 보다 훨씬 많은 앵커 박스로 재현율을 81%에서 88%로 향상시킬 수 있었습니다. (하지만 mAP는 살짝 감소합니다.)
Dimension clusters
기존에는 앵커 박스의 높이/너비 비율을 (aspect ratio) 사전에 정의했습니다. 하지만 사전의 정의한 앵커 박스 정보가 더 좋다면 학습이 더 쉬워질 것이기 때문에 YOLO v2 에서는 detection 데이터셋의 bounding box 에 대하여 K-Means 알고리즘을 적용해 앵커 박스를 미리 잘 정의하고자 합니다. 하지만 일반적인 Euclidean 거리를 중심에 대해 적용할 경우 Figure 2와 같이 ground truth 와 다른 엉뚱한 앵커박스가 군집화될 가능성이 높습니다. Figure 2의 파란색 박스는 ground truth, 빨간색 박스는 앵커 박스 prior 라 할때 왼쪽의 경우는 매우 비슷하더라도 중간과 오른쪽 앵커 박스 prior 에 비해 중심점 사이의 거리가 멀어 같은 군집으로 할당되지 못할 수 있습니다. 따라서 박스 크기와 무관하게 IOU가 높아지도록 하기 위해 $d(box, centroid) = 1-IOU(box, centroid)$를 Euclidean 거리 대신 사용함으로써 선택한 앵커 박스의 prior 가 좋은 IOU 값을 가지도록 K-Means 를 개량해서 사용합니다. 따라서 gound truth 와 IOU가 높은 값들끼리 뭉치게 되겠죠.

군집 수 $k$는 곧 앵커 박스의 수이므로 $k$가 커질수록 모델의 복잡도는 커지게 됩니다. Figure 3는 $k$에 따른 평균 IOU를 나타내고 $k=5$일 때 모델의 복잡도와 재현율의 적절한 trade-off 를 가졌다고 합니다. 특히, 군집화를 하지 않고 미리 정의한 hand-picked 앵커 박스 9개를 사용했을 때의 평균 IOU는 60.09 이고 군집화를 통해 뽑아낸 5개의 앵커 박스로 평균 IOU 61.0 을 달성했다고 합니다.

Direct location prediction
YOLO와 앵커 박스를 함께 사용했을 때 문제점은 Equation 1으로 좌표 $x, y$를 예측하는데, $t_x, t_y$의 제한된 범위가 없기 때문에 훈련 초기에 앵커 박스가 이미지 어디에도 위치할 수 있게 된다는 점입니다. 따라서 모델이 랜덤하게 초기화 되었을 때 수렴이 오래 걸리고 훈련 초기가 불안정해지게 됩니다.

YOLO v2 에서는 YOLO 에서와 같이 해당 그리드에 대해 Equation 2와 같이 상대적인 위치 좌표를 예측하는 방법을 선택합니다. 최종 feature map의 각 픽셀마다 5개의 bounding box (앵커 박스) 를 설정하고 각 박스마다 $t_x, t_y, t_w, t_h, t_o$를 예측합니다. $c_x, c_y$는 이미지 좌상단에서 해당 픽셀이 얼마나 떨어져 있는지 나타내는 오프셋이고 $p_w, p_h$는 군집화로 예측한 앵커 박스의 사전 높이/너비입니다. 중요한 점은 각 박스의 중심점을 $t_x, t_y$에 시그모이드 함수를 적용하고 $c_x, c_y$에 따른 오프셋으로 표현함으로써 0과 1사이의 값으로 표현한다는 것입니다.


예측하는 위치의 범위가 정해짐으로써 보다 안정된 학습이 가능해지고, 군집화를 통한 앵커 박스 prior 예측과 박스 중심을 예측하는 변환을 통해 mAP가 5% 정도 향상되었다고 합니다.
Fine-grained features
YOLO v2는 Figure 5와 같이 최종적으로 13x13 크기의 feature map 을 출력합니다. 기존의 7x7 보다 커졌지만 작은 물체에 대해서는 큰 물체에 비해 예측이 어렵습니다. 이를 보완하기 위해 YOLO v2 는 Figure 5의 노란색으로 표시된 부분처럼 직전 26x26 해상도의 feature map 을 마지막 13x13 feature map 에 이어주는 passthrough layer 를 추가합니다. 26x26x512 feature map 을 13x13 feature map 에 이어주기 위해 26x26 의 인접한 픽셀들을 서로 다른 채널로 쌓아 13x13x4 로 만드는 방식으로 13x13x2048 크기의 feature map을 만들어 최종 13x13x1024 feature map 에 이어붙입니다.
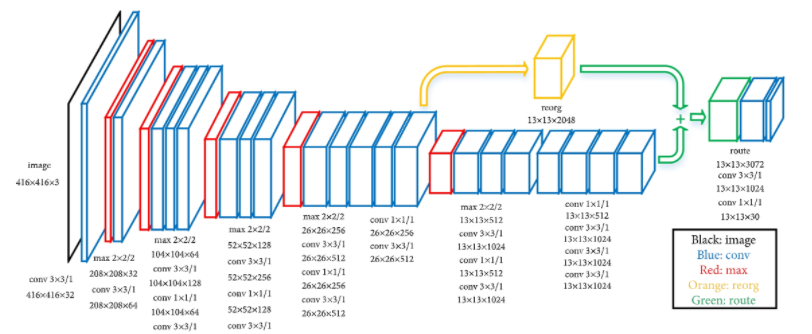
결과적으로 13x13x(1024+2048) 크기의 feature map 이 도출되며 마지막에 3x3 conv 와 1x1 conv 를 적용하여 13x13x125 의 최종 feature map을 도출하게 됩니다. (Figure 6) 마지막 채널 수가 125인 이유는 13x13 각 픽셀마다 5개의 앵커 박스가 존재하여 $t_x, t_y, t_w, t_h, t_o$와 20개의 클래스 확률을 예측하기 때문입니다. 이를 통해 mAP 가 1% 정도 향상되었다고 합니다.

Multi-scale training
YOLO v2 에서는 fully-connected lalyer 를 없앴기 때문에 입력 사이즈를 자유롭게 조절할 수 있습니다. 다양한 입력 사이즈에 대해 강건하기 만들기 위해 10 epochs 마다 입력 이미지의 크기를 {320, 352, ..., 608} 중에서 랜덤하게 선택하여 훈련합니다. 따라서 같은 모델로 다양한 해상도에 대해 훈련할 수 있어 더 강건해지고 작은 해상도에 대해서도 속도와 정확도를 높일 수 있습니다. Table 3은 multi-scale training 기법을 적용한 후 테스트 시의 입력 해상도만 달리한 결과입니다. 288x288 의 작은 해상도에서는 90 FPS로 Fast R-CNN의 성능과 거의 비슷하고 544x544 의 큰 해상도에서는 FPS가 40으로 낮아지지만 78.6이라는 최고 성능을 기록합니다. 결과는 Figure 7과 같습니다.

Summary
"Better" 섹션에서 살펴본 각 테크닉 적용에 따른 성능은 Table 2와 같습니다. Fully-connected layer 를 없앰으로써 속도를 높이고 앵커 박스 개념을 도입함으로써 최종적인 mAP를 기존 YOLO 대비 15% 정도 높였습니다. 또한, PASCAL VOS2012 테스트 데이터셋에 대한 결과는 Table 4와 같습니다. YOLO v2가 속도도 빠르면서 성능도 제일 좋은 것을 볼 수 있습니다.


Faster
기존 YOLO 에서는 마지막 fully-connected layer 가 7x7x1024x4096+4096x7x7x30 개의 파라미터가 사용되어 모델 전체의 파라미터 중 대부분을 차지합니다. YOLO v2 에서는 이 fully-connected layer 를 없애고 global average pooling 을 사용한 darknet-19 모델을 사용합니다. (Table 6) 1000개 클래스를 가진 ImageNet 데이터셋에 대해서는 224x224 사이즈에 대해서 160 epochs 정도 훈련 시킨 이후에 448x448 사이즈에 대해서 10 epochs 정도 fine-tuning 을 수행합니다. Detection 데이터셋에 대해 훈련시킬 때는 마지막 convolution layer (3x3x1024) 와 global average pooling layer 를 제거하고 3x3x1024 conv 와 1x1 conv 를 연속적으로 적용하여 최종적으로 125개의 채널을 예측하도록 모델의 마지막 부분을 수정합니다. 결과적으로 8.52B operation 이 필요한 기존 YOLO 에 비해 darknet-19는 5.58 operation 만이 필요하므로 더 빠르게 됩니다. (fully-connected layer 를 제거한 것에 비해 FLOPS 가 크게 줄지는 않은데, 파라미터 수 자체는 fully-connected layer 가 많지만 FLOPS 연산 자체는 convolution 이 차지하는 비중이 더 높기 때문입니다.)

Training
YOLO v2 또한 기존 YOLO와 같이 localization, confidence, classification loss 를 통해 훈련합니다.

Localization loss
객체의 위치를 학습하기 위한 목적함수입니다. 각 그리드의 각 박스별로 객체를 예측하도록 할당받거나 ($1_{ij}^{respobsible-obj}$) 할당받지 않는데 ($1_{ij}^{non-responsible-obj}$), 할당받은 박스에 대해서는 실제 ground truth 박스의 $x, y, w, h$를 예측하도록 훈련하고 할당받지 않은 박스에 대해서는 이 박스가 불필요하게 객체를 예측하지 않도록 하기 위해서 앵커 박스의 위치와 범위를 해당 그리드와 같게 줄여버립니다. 따라서 $x_{ij}^{anchor-center}, y_{ij}^{anchor-center}$는 0.5가 될 것이고 $w_{ij}^{anchor-default}, h_{ij}^{anchor-default}$는 1로 지정합니다. 마지막으로 $\lambda_{obj}^{coord}$는 객체를 포함하고 있는 박스에 대한 가중치로 1로 설정하고 $\lambda_{noobj}^{coord}$는 객체를 할당받지 못한 박스에 대한 가중치로 객체를 포함하고 있는 박스에 비해 중요도가 떨어지고 수가 더 많으므로 0.1로 설정합니다.
Confidence loss
해당 박스가 객체를 포함하는지 여부를 학습하기 위한 목적함수로 객체를 할당받은 박스에 대해서는 예측한 앵커 박스와 ground truth 사이의 IOU를 예측하도록 하고 (보통 1로 설정합니다.) 객체를 할당받지 못한 박스에 대해서는 0을 예측하도록 합니다. $\lambda_{obj}^{conf}$는 객체를 포함한 박스에 대한 가중치로 5로 설정하고 $\lambda_{noobj}^{conf}=0.5$로 설정합니다.
Classification loss
당연하게도 객체를 포함하고 있는 박스에 대해서만 적용하며 예측한 클래스 확률과 실제 클래스 확률과의 MSE 를 통해 학습합니다.
참조
- YOLO v2
- https://89douner.tistory.com/93?category=878735
- https://herbwood.tistory.com/17?category=856250
다음 포스트
'Machine Learning Tasks > Object Detection' 카테고리의 다른 글
| Object Detection - YOLO v3 Pytorch 구현 (1) (0) | 2021.06.11 |
|---|---|
| Object Detection - SSD (Single Shot MultiBox Detector) (0) | 2021.06.07 |
| Object Detection - DIoU, CIoU (0) | 2021.06.07 |
| Object Detection - YOLO v3 (2) | 2021.06.03 |
| Non-maximum Suppression (NMS) (2) | 2021.05.19 |



