ImageNet challenge 이후 Convolutional Neural Networks (Convnets)는 높은 성능을 위해 점점 커지고 깊어졌지만 이에 대한 반대급부로 한정된 computational 리소스를 가진 임베디드 시스템에 모델을 deploy하기가 어려워지고 FLOPS의 증가로 inference 시간이 길어지면서 실시간 서비스가 중요한 웹 서비스에 부적합하게 되었습니다.
이 문제를 해결하기 위해 모델의 불필요한 부분을 제거하거나 (pruning), 모델 파라미터를 표현하는 bit 수를 감소시키는 (quantization) 등의 다양한 모델 압축 기법이 연구되고 있습니다. 이번 포스트에서는 그 중 모델의 영향력이 적은 파라미터를 통째로 제거하는 pruning 기법에 관해 살펴보려 합니다.
기존의 pruning 은 모델의 파라미터 중 작은 절대 크기를 가진 파라미터 일정 비율을 제거하고 다시 훈련시키는 (find-tuning) 방식을 주로 사용했습니다. 하지만 제거되는 파라미터의 대부분이 fully-connected layer의 파라미터이고 FLOPS 에 대부분의 영향을 미치는 convolution 파라미터가 잘 제거되지 않다보니 pruning을 하더라도 실제 inference 시간이 크게 줄지 않습니다. 또한, convolution filter의 일부분이 제거되면 sparsity가 강제되어 sparse matrix 연산을 지원하는 BLAS 라이브러리가 필요합니다.
이 논문에서는 기존 pruning과 달리 구조화된 (structured) filter pruning 방법을 제안합니다. 기존 방법처럼 파라미터를 개별적으로 제거하는 것이 아니라 filter를 통짜로 제거하는 것이죠. 이를 통해 sparsity를 위한 별도의 라이브러리가 필요하지 않고, convolution filter를 직접적으로 제거하다보니 FLOPS가 줄어 inference 시간을 크게 줄일 수 있고 목표로 하는 speed up을 쉽게 설정할 수 있습니다.
Pruning filters
먼저 $i$ 번째 feature map의 height, width, channel 을 각각 $h_i, w_i, c_i$로 정의하겠습니다. $i$ layer에서 ($x_i\in R^{n_i\times h_i\times w_i}$) $i+1$ layer의 ($x_{i+1}\in R^{n_{i+1}\times h_{i+1}\times w_{i+1}}$) feature map으로 변환하기 위한 convolution 연산에는 $n_{i+1}$ 개의 3D filter ($F_{i,j}\in R^{n_i\times k \times k}$)가 필요합니다. 각 filter가 하나의 output feature map을 만들게 되는 것이죠. 정리하면 $F_i \in R^{n_i\times n_{i+1}\times k\times k}$의 kernel matrix를 구성하게 되고 $n_{i+1}n_i k^2 h_{i+1}w_{i+1}$ 의 연산이 소요됩니다.

위의 그림처럼 $i+1$ layer의 $j$ 번째 output feature map을 만들기 위한 filter를 제거할 경우 $n_i k^2 h_{i+1}w_{i+1}$의 연산이 줄게 됩니다. $i+1$ layer 입장에서도 feature map의 개수가 하나 줄었으니 다음 layer를 위한 convolution 연산도 $n_{i+2} k^2 h_{i+1}w_{i+1}$ 만큼 줄게됩니다. 이를 일반화해서 $i$ layer의 filter를 $m$개 만큼 제거했을 경우 $i,i+1$ layer의 연산을 $m/n_{i+1}$ 배 만큼 줄이게 됩니다.
Determining which filters to prune within a single layer
그렇다면 어떤 filter를 제거해야 할까요? 제거할 filter를 찾기 위한 상대적인 중요도를 측정하기 위해 $n_{i+1}$개의 filter 에 대해서 $\sum |F_{i,j}|$를 측정합니다. (L1-norm) 이는 filter의 전체적인 크기가 작으면 해당하는 output feature 의 크기 또한 작아져 영향을 덜 미치게 될 확률이 높아지기 때문입니다. 결과적으로 각 filter의 L1-norm을 측정하여 작은 것부터 크기 순으로 나열하고 미리 정한 비율에 따라 작은 $m$개의 filter를 제거합니다. 제거하게 되면 이후 layer의 대응되는 feature map 또한 제거되고 남은 filter들은 pruning된 새로운 모델에 복사됩니다.
Determining single layer's sensitivity to pruning
모델의 각 layer마다 pruning에 따른 민감도를 파악하기 위해 CIFAR-10에 대해 훈련시킨 VGG 모델에 대하여 각 layer에 대해 개별적으로 pruning을 진행하고 성능을 얻은 실험을 진행하였습니다.

위 그림을 보면 pruning 비율이 높아질 수록 당연히 성능이 낮아지고 같은 비율을 pruning 했음에도 각 layer마다 민감하게 받아들이는 정도가 달라집니다. 이 결과에 기반하여 각 layer의 pruning 비율을 결정하고 pruning에 민감한 layer에 대해서는 매우 적게 pruning 하거나 아예 하지 않습니다. 또한, ResNet 같이 여러 개의 stage로 이루어진 모델의 경우 각 stage안의 여러 layer들의 pruning 민감도가 비슷하여 한 stage에 대해서는 같은 pruning 비율을 적용합니다.
Pruning filters across multiple layers
위에 언급한 한 layer에 대한 pruning을 전체 네트워크에 어떤 방식으로 적용할까요? 기존 방식은 한 layer에 대해 pruning을 하고 fine-tuning 하는 것을 layer by layer로 반복합니다. 이 방식은 굉장히 시간이 오래 걸리기에 논문에서는 one-shot으로 여러 개의 layer에 동시에 pruning을 적용하는 방법을 제안합니다.
먼저 independent pruning으로 각 layer마다 다른 layer에 독립적으로 pruning할 filter를 결정하는 방법으로 그 전 layer에서 제거된 filter를 고려하지만 greedy pruning으로 이전 layer에서 제거된 filter를 고려하지 않고 L1-norm을 계산합니다. 밑의 그림을 보면 independent pruning은 전 layer에서 제거된 파란 색깔의 filter를 정할 때 노란색 부분을 L1-norm 계산에 포함시키지만 greedy pruning은 초록 색깔의 filter를 제거할 때 노란색 부분을 L1-norm 계산에 포함시키지 않습니다.

AlexNet이나 VGGNet 같은 경우 상대적으로 단순한 모델로 각 layer 마다 pruning을 진행하면 됩니다. 하지만 ResNet은 shortcut connection으로 구성된 residual block으로 구성되어 조심스럽게 pruning 되어야 합니다. 밑의 그림은 residual block의 pruning 방법을 표현한 그림으로 residual block의 첫 번째 layer는 output feature map 크기에 영향을 미치지 않기에 독립적으로 pruning 됩니다.
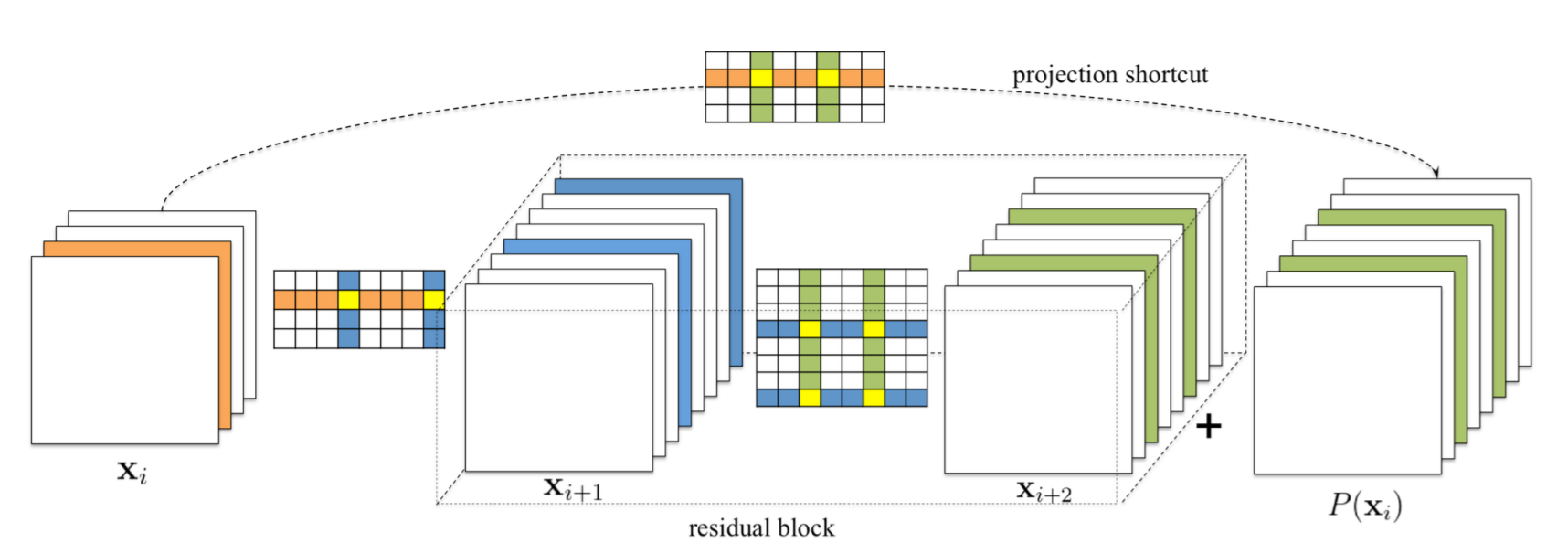
하지만 residual block의 두 번째 layer와 identity projection은 최종 output feature map 단에서 더해지기 때문에 residual block의 두 번째 layer에서 제거된 feature map은 projection shortcut feature map에서도 제거되어야 합니다. 이때, identity projection 의 feature map이 의미적으로 더 중요하기 때문에 residual block의 두 번째 layer의 pruning 위치는 identity projection pruning (1x1 convolution에서 pruning) 위치에 따라 결정됩니다.
Retraining pruned networks to regain accuracy
Pruning을 진행한 이후에는 성능 감소를 보완하기 위해 다시 훈련시키는 fine-tuning의 과정을 거쳐야 합니다. 이를 하기 위해서는 1. layer by layer로 진행하거나 2. 전체 모델에 대해 pruning을 진행한 후 한번에 fine-tuning 하는 방법이 있습니다. 논문에서는 layer by layer 방식 대신 2번 방식의 one-shot retraining 방법을 사용하며, 성능 감소를 최소화하기 위해 layer 마다 pruning 민감도에 따른 비율을 다르게 결정합니다.
Experiment
실험은 VGG와 ResNet에 대해 진행되었고 pruning 이후에는 적은 파라미터를 가진 새로운 모델을 생성하여 pruning 이후 남은 파라미터를 복사합니다. 또한 convolution filter가 제거되었으면 해당되는 batch normalization의 파라미터 또한 제거합니다.
Experiment result
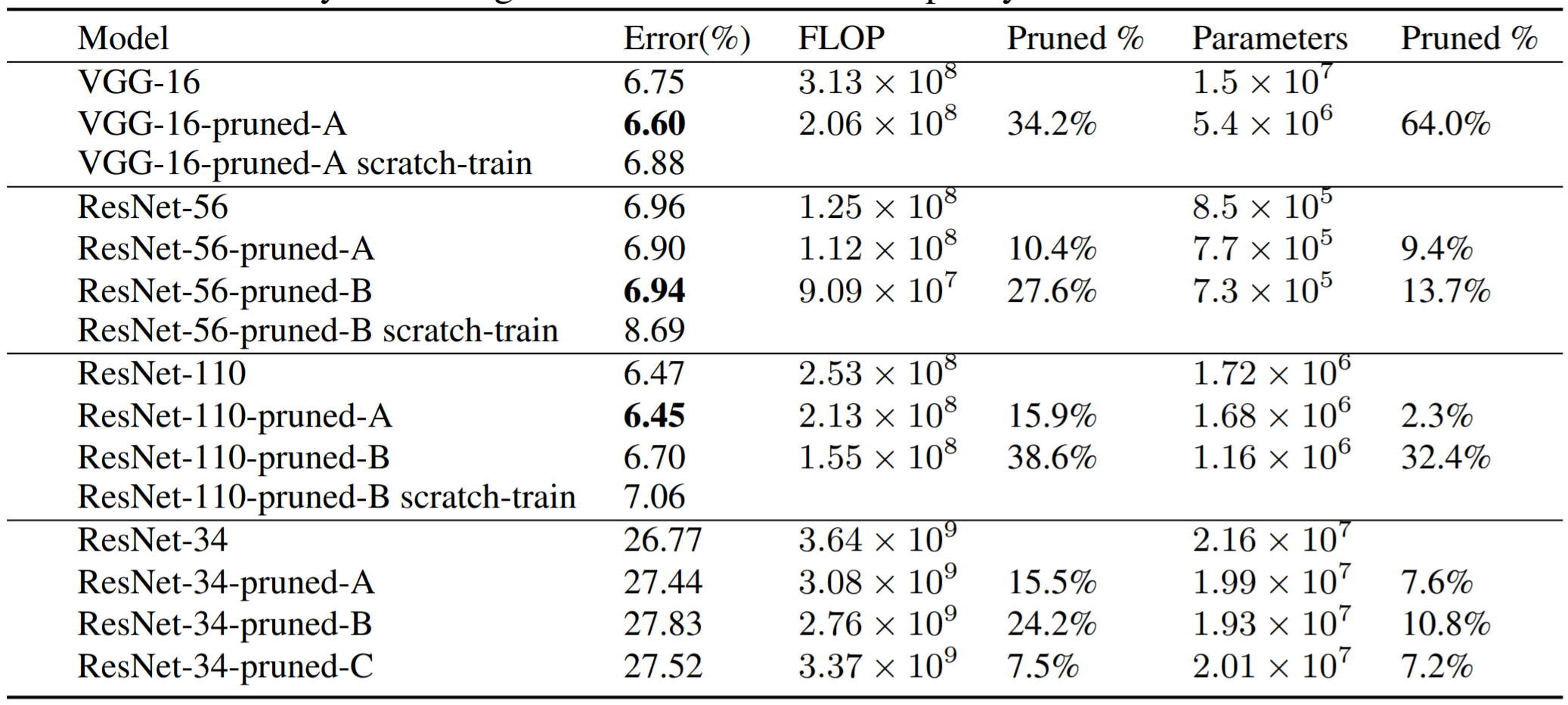
CIFAR-10에 대한 VGG-16, ResNet-56,110 pruning 결과와 ImgeNet에 대한 ResNet-34 pruning 결과는 위 표와 같습니다. Scratch-train이라 적힌 부분은 pruning 이후 남은 파라미터를 새로운 모델에 복사하지 않고 새로운 모델 자체를 처음부터 다시 훈련시키는 경우를 말합니다.
VGG의 경우 입력 사이즈가 작아 첫 layer와 마지막 feature map 512개를 가진 layer는 pruning에 견고합니다. 반면 두 번째 layer를 지나치게 pruning 할 경우 성능이 지나치게 감소하고 retraining을 하여도 성능이 회복되지 않습니다. 따라서 첫 번째 layer와 마지막 몇 개의 layer에 대해 50% pruning을 통해 FLOPS를 34% 줄이면서 비슷한 성능을 가진 모델을 생성하였습니다.
ResNet에서는 feature map의 개수가 바뀌는 stage의 첫 번째, 마지막 residual block과 깊은 layer가 얕은 layer보다 pruning에 민감하여 stage마다 pruning의 비율을 달리 하였습니다. 또한, residual block의 두 번째 layer는 pruning에 민감하여 residual block의 첫 번째 layer를 pruning 하는 것이 더 효율이 좋았다고 합니다.
Comparison with pruning random filters and largest filters
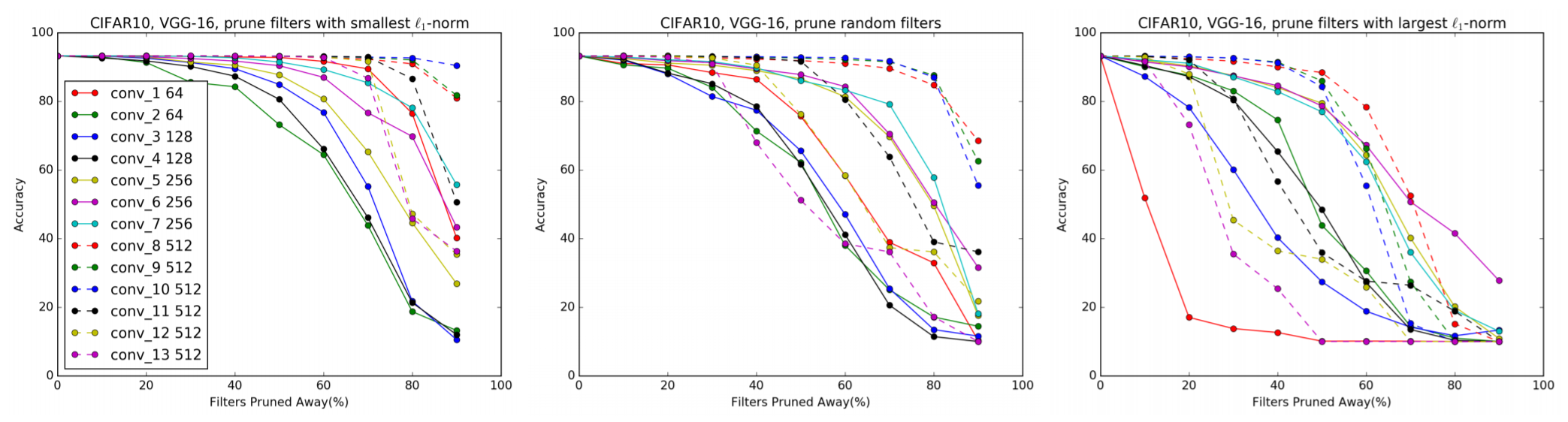
L1-norm이 작은 순을 제거이 랜덤하거나 큰 filter를 제거하는 것보다 얼마나 효율이 좋을까요? 밑의 그림을 보면 바로 알 수 있습니다.
Comparison with activation-based feature map pruning
Filter의 L1-norm이 아닌 activation 단에서의 크기를 통해 해당하는 filter를 제거하는 방법과 pruning 성능을 비교해 보았습니다. $N$ 개의 훈련 데이터를 forwarding 해서 각 layer의 output feature map 단의 평균, 분산 등의 통계치를 추출하고 통계치가 작은 feature map에 해당하는 filter를 제거합니다. 분산같은 경우는 덜 중요한 feature 는 데이터에 따라 거의 비슷한 값 (작은 분산)을 가진다는 실험적인 동기에서 비롯되었습니다.

위의 그림에서 볼 수 있듯이 언급한 L1-norm을 통해 pruning할 filter를 선택하는 방식이 제일 효율적입니다.
홍머스 정리
- Independent pruning과 greedy pruning이 구체적으로 어떻게 사용되는지 ?
참조
'Machine Learning Models > Covolutions' 카테고리의 다른 글
| Slimmable Neural Networks (0) | 2021.03.14 |
|---|---|
| Learning Efficient Convolutional Networks through Network Slimming (0) | 2021.03.13 |
| EfficientNet (0) | 2021.03.10 |
| DenseNet (0) | 2021.03.03 |
| NASNet (0) | 2021.03.02 |



