ResNet이 layer의 shortcut connection이 convolution layer의 깊은 적층을 가능하게 보인 이후, 각 layer를 shortcut으로 잇고자 하는 다양한 architecture들이 발표되었습니다. DenseNet은 2016년에 발표된 CNN architecture중 하나로 CNN의 반복된 각 layer를 dense하게 연결한 구조입니다. DenseNet은 다음 그림과 같이 이전 layer들의 feature map이 다음 layer의 입력으로 dense하게 연결하는 구조를 가지고 있습니다.
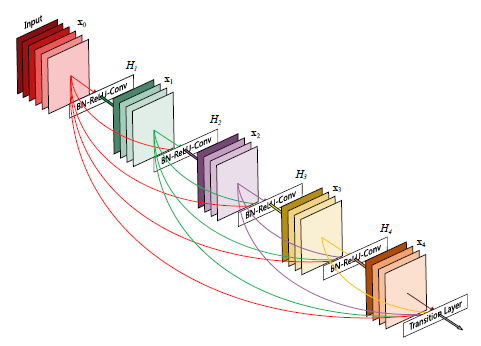
입력 layer의 feature map은 이후 모든 layer의 입력으로 연결되고 그 다음 layer의 feature mpa은 그 이후의 모든 layer의 입력으로 연결됩니다. 따라서 layer가 $L$개 있다면 총 $\frac{L(L+1)}{2}$개의 연결고리가 생기는 것이죠.
이러한 연결로 인해,
-
기존 architecture에 비해 상대적으로 더 적은 파라미터로 높은 성능을 얻을 수 있고
-
논문에서는 narrow feature map이라 표현합니다. 실제로 DenseNet에서 사용하는 feature map 차원은 12로 다른 architecture에 비해 매우 적습니다.
-
이것이 가능한 이유는 기존 ResNet 류에서는 identity mapping이 convolution 연산 결과물과 element-wise로 더해지지만 DenseNet은 전 layer의 feature map들을 concatenate 함으로써 전 layer의 정보를 그대로 유지하기 때문입니다.
-
-
모든 layer가 마지막 단의 목적 함수와 입력 이미지와 직접적인 접근이 가능해져서 vanishing gradient 현상이 완화되고 더 깊은 CNN architecture를 설계할 수 있습니다.
DenseNet
DenseNet과 ResNet의 가장 큰 차이점은 DenseNet은 전에 있던 모든 layer의 feature map이 concat되어 다음 layer의 입력으로 들어간다는 점입니다. 즉, $l$번째 layer의 feature map $x_l$은,
$x_l = H_l (concat[x_0, x_1, ..., x_{l-1}])$
로 결정됩니다. 여기서 $H_l$은 non-linear transformation으로 Batch Normalization - ReLU - 3 x 3 convolution의 operation으로 이루어져 있습니다.
Growth rate
Growth rate는 각 $H_l$이 생성하는 feature map의 개수입니다. 위에서 언급했듯이 DenseNet의 layer는 앞선 layer의 feature map에 직접적인 접근이 가능하기 때문에 growth rate를 충분히 낮게 잡아도 좋은 성능을 낼 수 있다고 합니다. 또한, concatenation으로 feature map이 합쳐지다 보니 growth rate가 크다면 feature map의 채널 개수가 지나치게 커지는 것을 방지하기도 합니다.
Bottleneck layers
주어진 입력의 채널 개수보다 더 많은 채널을 활용하기 위해 1 x 1 convolution이 DenseNet에도 사용됩니다. 즉 $k$개의 growth rate를 가진 feature map이 들어왔을 때, $H_l$ 은 Batch Normalization -ReLU - 1 x 1 convolution (4k) - Batch Normalization - ReLU - 3 x 3 convolution (k) 의 operation 조합이 되는 것이죠.
주의해야 할 점은 일반적으로 bottleneck layer의 1 x 1 convolution은 채널의 개수를 줄이기 위해 사용되나 여기서는 4k 개 만큼 늘리고 k 개로 줄인다는 점입니다. 이것이 실험적으로 더 좋은 성능을 이끌어냈다고 합니다.
Transition layers
Transition layer는 pooling을 통해 feature map의 크기를 줄이는 역할을 합니다. Dense하게 연결된 여러 개의 layer가 하나의 dense block을 구성하고 dense block 사이에 transition layer가 삽입되어 feature map 크기를 통제합니다. Transition layer는 Batch Normalization - ReLU - 1 x 1 convolution - 2 x 2 average pooling의 순으로 동작합니다.
또한, 모델의 압축도를 더 높이기 위하여 transition layer의 1 x 1 convolution에서 채널 수를 $\theta$만큼 줄입니다. $\theta=1$이라면 feature map의 채널이 그대로 유지됩니다. 논문에서는 $\theta=0.5$를 사용하고 있고, 그렇다면 feature map의 크기뿐만 아니라 채널 개수도 절반으로 줄어들게 됩니다.
Implementation details
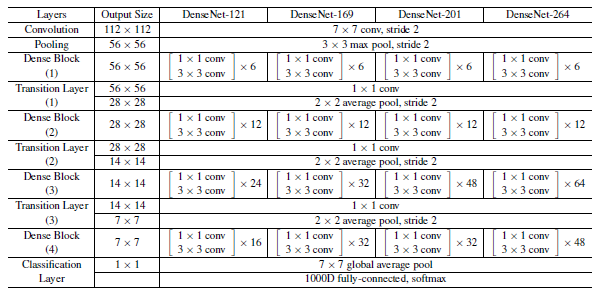
$k=32$, ImageNet 데이터셋에 대한 DenseNet 구성도는 다음과 같습니다. Dense block 내의 3 x 3 convolution 은 feature map의 사이즈를 유지하기 위해 양쪽에 1칸씩 zero-padding합니다. 첫 번째 convolution layer의 feature map 채널은 2k개입니다. CIFAR나 SVHB 같은 크기가 작은 데이터셋에 대해서는 3개의 dense block이 들어갑니다.
EXPERIMENT
Classification Results on CIFAR, SVHN, ImageNet

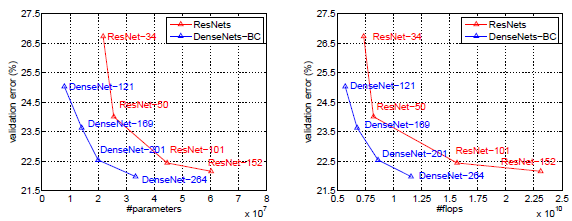
C10, C100은 각각 CIFAR-10과 CIFAR-100이며 +는 data augmentation을 나타냅니다. DenseNet-BC는 $\theta=0.5$를 적용한 모델이며 기존 ResNet에 비해 더 적은 파라미터로 높은 성능을 보였습니다.
ImageNet에 대해서도 더 적은 파라미터로 낮은 error 를 달성함을 보였습니다. 특히, FLOPS 연산량에 대해서도 동일한 FLOPS에 대해서도 성능 우위를 보였습니다.
Feature reuse
DenseNet은 설계 상 이전 layer의 모든 feature map이 concat되서 입력으로 들어갑니다. 이것은 feature 전파 측면에서 유리한데, 이전의 feature를 그대로 재사용할 수 있으므로 더욱 압축된 모델을 만들 수 있습니다. 그렇다면 각 layer에 연결된 feature map들은 얼마나 재사용될까요?

위 그림은 각 dense block마다 해당 layer의 feature map (source)이 다른 layer의 (target)에 연결되었을 때 적용된 파라미터의 평균 크기를 ($L_1$ norm) 나타낸 것입니다. 파라미터의 평균 크기는 feature map의 채널 개수로 normalize되었기 때문에 0에서 1사이의 값으로 표현됩니다.
-
앞선 layer에서 추출된 feature map이 그 이후 layer에서도 골고루 쓰이는 것을 확인할 수 있습니다.
-
마지막의 검은 사각형인 transition layer 부분을 보면, 앞선 layer의 feature map을 골고루 쓰는 것을 확인할 수 있습니다.
-
두 번째, 세 번째 dense block의 맽 윗줄을 보면 전 transition layer의 output은 상대적으로 강도가 매우 낮습니다. 이는 transition layer의 출력이 잉여 feature들을 사용한다고 생각할 수 있고 위에 언급한 $\theta$를 통한 모델 압축이 신빙성을 얻습니다.
홍머스 정리
- 모든 layer를 잇는다. Densely connect!
참조
'Machine Learning Models > Covolutions' 카테고리의 다른 글
| Pruning Filters for Efficient Convnets (0) | 2021.03.11 |
|---|---|
| EfficientNet (0) | 2021.03.10 |
| NASNet (0) | 2021.03.02 |
| Xception (0) | 2021.02.28 |
| ShuffleNet V2 (0) | 2021.02.27 |



