Xception은 eXtreme Inception의 약자로 기존 Inception 모델이 채널, 공간 correlation을 분리한 것을 depthwise separable convolution으로 강화한 모델입니다. Inception V3과 비슷한 수의 파라미터를 가지면서 image classification에서 더 좋은 성능을 이끌어 냈습니다.
Inception
일반적인 convolution은 높이, 너비의 spatial dimension과 channel dimension을 함께 correlation한 결과를 도출합니다. Inception은 이와 다르게 먼저 서너 개의 1 x 1 convolution으로 channel correlation을 먼저 매핑한 후 3 x 3, 5 x 5 convolution을 수행합니다. Inception의 기본 가정은 채널과 공간의 convolution을 분리하는 것입니다.

위 그림처럼 1 x 1 convolution으로 input feature를 3, 4개의 segment로 나눈 후에 각 segment에 대한 일반 convolution 연산을 한 후 concat으로 합칩니다. 논문에서의 motivation은 여기서 나오는데요. 애매하게 3, 4개 정도로 나눌 것이 아니라 channel과 spatial correlation을 완벽하게 분리하는 것이 어떠냐는 것입니다. 즉, 밑의 그림처럼 1 x 1 convolutoin으로 channel correlation을 수행하고 모든 output channel 각각에 대해서 spatial convolution을 수행하자는 것이죠.

Depthwise separable convolution
depthwise separable convolution은 입력 채널 각각에 대해 공간 convolution인 depthwise convolution을 수행하고 1 x 1 convolution을 수행한 것입니다. 즉, depthwise + pointwise convolution이며, 간단하게 separable convolution이라고도 합니다. 그림 위의 그림과 depthwise separable convolution은 어떤 차이가 있을까요?
-
Depthwise separable convolution은 channel-wise spatial convolution을 먼저 수행한 후에 1 x 1 convolution을 수행합니다. 어짜피 이 block들이 여러 개 쌓이기 때문에 순서는 크게 중요하지 않다고 합니다.
-
기존 Inception 모듈에는 각 convolution 이후에 ReLU와 같은 non-linear activation을 추가합니다. 하지만, depthwise separable convolution은 각 convolution 사이에 non-linear activation이 없습니다.
따라서 어찌 보면 Inception 모듈은 channel을 적당히 segment 했으므로 일반적인 convolution과 depthwise separable convolution의 중간 단계에 있다고 볼 수 있습니다. 논문에서는 매우 강한 Inception 모듈, Inception 모듈을 depthwise separable convolution으로 교체하여 eXtreme Inception 모델을 제안합니다.
Xception
Xception은 Inception에서 더 나아가 channel, spatial convolution을 depthwise separable convolution으로 완벽히 분리하자는 것이 골자입니다. 전체 architecture는 다음과 같습니다.
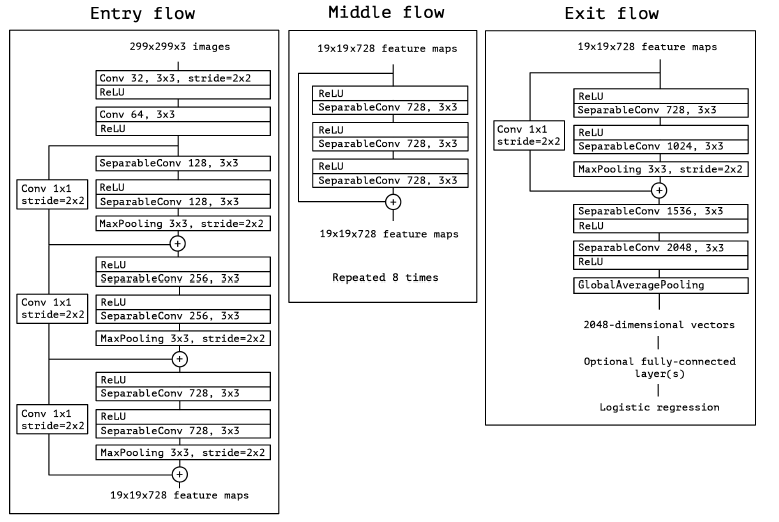
Depthwise separable convolution과 max-pooling으로 하나의 블락을 구성하고 이를 residual connection으로 연결 한 것이 하나의 모듈이 됩니다. 이를 여러 개 쌓은 것이죠.
실험
Classification performance
비슷한 수의 파라미터를 가지는 Inception V3에 비해 image classification 정확도가 향상된 것을 볼 수 있습니다.

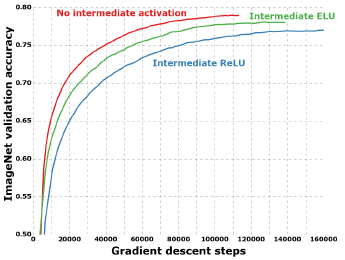
Effect of an intermediate activation after depthwise convolution
위에서 언급했듯이 depthwise separable convolution은 기존 Inception module과 달리 convolution 사이에 non-linear activation을 삽입하지 않습니다. 이는 non-linear activation을 적용하는 데는 feature의 개수가 중요하여 deep feature space에서는 효과적일 수 있으나, depthwise convolution은 하나의 channel에 대해서만 convolution을 진행하므로 non-linear activation을 적용할 시 오히려 정보 손실이 발생합니다.
홍머스 정리
- Extreme Inception
- 아예 채널 각각을 한땀한땀 convolution해보자
- Depthwise separable convolution
참조
'Machine Learning Models > Covolutions' 카테고리의 다른 글
| EfficientNet (0) | 2021.03.10 |
|---|---|
| DenseNet (0) | 2021.03.03 |
| NASNet (0) | 2021.03.02 |
| ShuffleNet V2 (0) | 2021.02.27 |
| ShuffleNet (0) | 2021.02.27 |



