딥러닝 모델의 연산량을 측정하는 FLOPS는 딥러닝 모델 속도 측정에 관해 얼마나 정확한 지표일까요? ShuffleNet V2는 FLOPS 이외의 memory access cost 나 gpu/arm device 등 플랫폼에 따른 다른 요소들도 고려한다고 주장하며, 효율적인 CNN 모델 설계를 위한 4 가지 가이드라인을 제시합니다. 이 가이드라인을 기반으로 기존의 ShuffleNet을 개선한 모델을 제안합니다.
Introduction
Xception, MobileNet, ShuffleNet 등의 경량화 모델에서 group convolution과 depthwise convolution은 굉장히 중요한 요소로 작용합니다. 이러한 요소를 많이 사용하는 것은 이론상으로 FLOPS를 줄이지만 감소된 만큼의 속도 증가가 이루어질까요?
먼저, CNN에서의 FLOPS는 convolution의 더하기, 곱하기 연산의 총합입니다. 근본적으로 FLOPS는 딥러닝 모델의 연산량을 근사하지만 실제 원하는 직접적인 지표, 속도나 latency 측면에서는 간접적인 지표입니다. 실제 FLOPS와 속도가 정확히 반비례하지 않기 때문입니다.

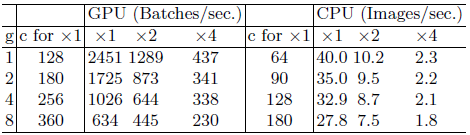
위 그림은 각 경량화 모델의 GPU, ARM 플랫폼에서의 속도 측정 결과입니다. 각 모델의 FLOPS가 비슷하다 하더라도 속도 (GPU에서는 1초에 처리하는 BATCH 량, ARM에서는 1초에 처리하는 이미지 개수) 가 천차만별입니다. 따라서, FLOPS만을 고려한 모델 설계는 최적의 모델을 도출하는 데 한계가 있습니다.
FLOPS와 우리가 직접적으로 알고 싶은 속도에 이러한 간극이 발생하는 이유는,
-
FLOPS에는 속도에 영향을 미치는 메모리 접근 비용, 병렬 정도 등을 고려되지 않습니다.
-
GPU, ARM 등의 플랫폼마다 같은 FLOPS라 하더라도 실행 시간이 다릅니다. 예를 들어 행렬 곱연산을 하기 위한 tensor decomposition 기술은 FLOPS는 75% 줄이더라도 GPU에서는 오히려 더 느려집니다. 밑의 그림에서 볼 수 있듯이 같은 연산이라 하더라도 플랫폼마다 실행 시간에서 차지하는 비중이 달라집니다.

위 그림에서 볼 수 있듯이 실행 시간의 절반 이상은 convolution 연산이 차지하지만 data I/O, ReLU나 더하기 등의 elementwise operation의 실행 시간도 무시할 수 없습니다.
결론적으로 FLOPS와 직접적인 지표인 speed 등을 경량화 모델 성능 비교 지표로 사용해야 되며, 각 지표는 타겟 플랫폼에 맞추어 검증되어야 합니다.
Guidelines
Xception, MobileNet, ShuffleNet 등의 경량화 모델에서의 핵심은 group convolution과 depthwise convolution 입니다. 과연, 이 요소를 어떻게 활용하여야 할까요?
Equal channel width minimiezs memory access cost (MAC)
대부분 경량화 모델의 대부분 연산을 차지하는 1 x 1 convolution을 생각해 보겠습니다. 입력 채널 $c_1$, 출력 채널 $c_2$가 있을 때, 1 x 1 convolution의 FLOPS는 $hwc_{1}c_{2}$가 됩니다.
반면, 메모리 접근 횟수는 (MAC) 어떻게 될까요? 연산을 위해서 입력, 출력의 feature map에 접근할 것이고 연산을 위한 kernel에 접근할 것입니다. 따라서 1 x 1 convolution의 MAC 는 $hw(c_1+c_2) + c_{1}c_{2}$ 가 됩니다. 1 x 1 convolution에서 MAC와 FLOPS의 관계를 다음과 같이 표현할 수 있습니다.
$MAC \geq 2\sqrt{hw\times FLOPS} + \frac{FLOPS}{hw}$
따라서 MAC는 FLOPS에 의해 하한을 가지게 되고 $c_1$과 $c_2$가 같을 때 equality가 성립합니다. 이를 실험적으로 검증해보기 위해 2개의 convolution layer을 가진 block을 10개 stack한 후의 속도를 측정해봅니다. 이 때, $c_1$과 $c_2$가 거의 같을 때 가장 빠른 것을 확인할 수 있습니다. (공정한 비교를 위해 각 케이스마다 총 FLOPS는 같습니다.)

Excessive group convolution increases MAC
Group convolution은 파라미터 수와 연산량을 그룹 수만큼 줄이게 되는데 그럼 그룹을 무작정 많이 늘리면 좋은 것일까요? 1 x 1 group convolution의 FLOPS는 $hwc_{1}c_{2}/g$이고 MAC는 어떻게 될까요?
$MAC = hw(c_1 + c_2) + \frac{c_{1} c_{2}}{g} = hwc_1 + \frac{FLOPS\times g}{c_1} + \frac{FLOPS}{hw}$
따라서, 입력 feature map이 고정되어 있을 때 그룹 수 g가 증가하면 MAC가 증가합니다. 이를 검증하기 위해 pointwise group convolution을 10층 쌓고 그룹 별로 속도를 비교합니다. 그룹 수가 증가할수록 속도가 급감하는 것을 확인할 수 있습니다.
결과적으로 그룹 수를 무작정 늘리는 것이 아니라 타겟 플랫폼에 맞추어 신중하게 선택해야 합니다. 그룹 수를 늘려 상대적인 feature 수를 크게 가져가더라도 속도 측면의 감소가 일어날 수 있습니다.
Network fragmentation reduces degree of parallelism
Network fragmentation은 큰 하나의 덩어리 연산을 여러 작은 연산으로 쪼개는 것으로 여기서 fragmented operators에는 각 convolution이나 pooling operator가 해당됩니다. 이러한 fragmentation은 정확도 측면에서 장점이 될 수 있으나 GPU같은 병렬 계산에 특화된 플랫폼에서는 동기화 등의 추가 오버헤드가 발생하여 안 좋은 영향을 미칠 수 있습니다.
이를 확인하기 위해 1 x 1 convolution을 다양한 fragment 전략으로 설계해서 10층을 쌓고 속도를 측정해봅니다. 4-fragment 로 설계했을 시, 1-fragment에 비해 속도가 감소한 것을 볼 수 있습니다.


Element-wise operations are non-negligible
FLOPS 계산에는 element-wise 연산 효과가 무시됩니다. 하지만 실행 시간에서 element-wise operation을 무시할 수 없는 비중을 차지하고 있습니다. Element-wise operations는 텐서의 원소 각각에 대한 계산으로 ReLU, 텐서 더하기, bias 더하기 등을 말합니다. 이 연산의 특징은 작은 FLOPS 대비 MAC가 높은 것으로 depthwise convolution 또한 이 같은 특징을 가지고 있습니다.
이를 검증하기 위하여 resnet block에서 element-wise operations인 ReLU와 shortcut을 제거했을 때의 속도를 측정해봅니다. 둘 다 제거되었을 때 20%의 속도 측정을 확인할 수 있습니다.

Discussion
위에 4가지 가이드라인에 비추어 봤을 때, 기존 모델은 어떤 가이드라인을 준수하지 못했을까요? 먼저 ShuffleNet은 지나친 group convolution에 의존하고 (가이드라인 2) 해당 유닛안의 bottleneck 채널 수가 줄었다가 늡니다. (가이드라인 1) MobileNet v2는 inverted bottleneck structure로 가이드라인 1에 위배되고 큰 feature map 에 대해 ReLU를 적용합니다. (가이드라인 4)
가이드라인을 적용하여 경량화 모델을 어떻게 개선할 수 있을까요?
ShuffleNet V2
기존 ShuffleNet은 경량화 모델에서의 feature의 개수를 늘리기 위해 pointwise group convolution과 bottleneck structure, 그리고 channel shuffle을 사용했습니다. 또한 마지막에 elementwise operation 인 더하기가 있습니다. 이는 모두 위의 가이드라인에 위배됩니다.

(a), (b)는 기존 ShuffleNet 유닛, (c), (d)는 ShuffleNet V2 유닛입니다. (b)와 (d)는 입력 사이즈를 절반으로 줄일 때 사용되는 유닛이며 DWConv 는 depthwise convolution, GConv는 group convolution입니다. ShuffleNet V2의 차이점을 뭘까요?
-
입력 단에서 channel split이 존재합니다. 입력 feature map을 절반으로 나누어 각각 왼쪽, 오른쪽 path로 보냅니다.
-
1 x 1 convolution에 더이상 group convolution을 적용하지 않습니다. 이는 가이드라인 2를 따르면서 동시에 channel split이 입력에서 이미 수행되었기 때문입니다.
-
오른쪽 path에 3개의 convolution layer가 존재하는데 가이드라인 1을 따르기 위해 입력/출력 채널 개수를 같게 맞췄습니다.
-
마지막에서 elementwise operation인 add 대신에 concat을 합니다 (가이드라인 4). 그 후 channel shuffle을 수행합니다.
-
(d)의 경우 입력 사이즈를 줄이면서 feature 개수를 2배 증가시키기 위해 처음 channel split이 삭제됩니다.
전체 architecture는 다음과 같습니다. 큰 차이점은 마지막 global average pooling 전 layer에 1 x 1 convolution 을 추가하여 feature들을 섞어줍니다.

마지막으로 ShuffleNet V2에서는 입력의 절반 feature가 다음 block에 그대로 사용됩니다. (마지막에 add가 사용되었으므로) 이는 DenseNet이나 CondenseNet의 feature reuse와 동일한 개념인데요. 이 절반의 feature가 인접한 layer에서 강하게 영향을 끼치니 성능에 긍정적인 영향이 있고 block끼리의 거리가 멀어지면 자연스레 영향력이 감소하므로 feature redundancy를 줄일 수 있습니다.
실험
ShuffleNet V2는 효율적인 모델 설계로 주어진 FLOPS 하에서 많은 feature를 사용할 수 있어 성능이 좋고 MAC를 고려했기 때문에 실제 inference speed도 빠릅니다. ShuffleNet에서와 마찬가지로 ImageNet 2012 classification dataset으로 실험을 진행하였습니다.
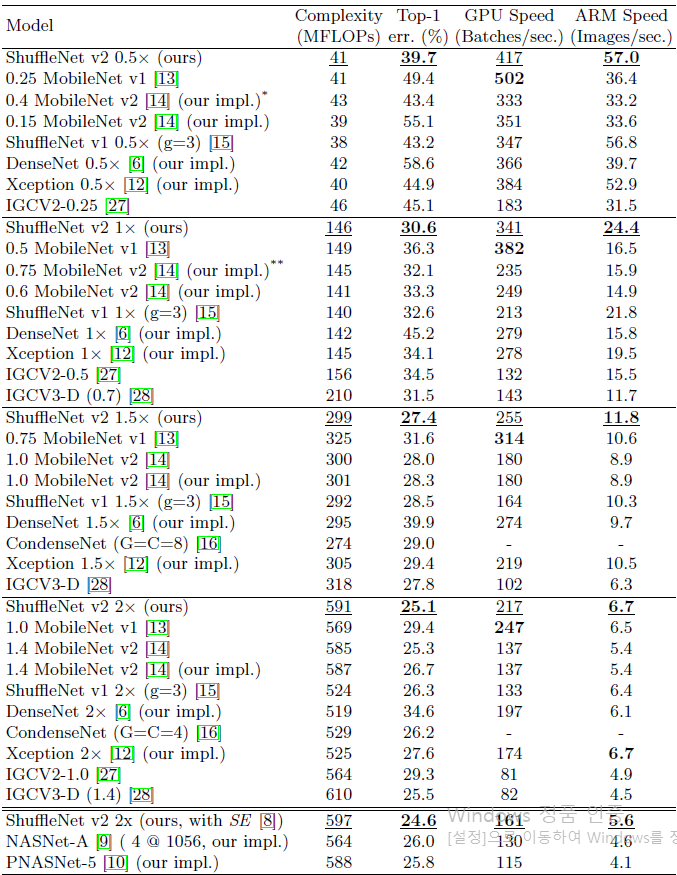
위의 표는 각 FLOPS 범위마다 다른 경량화 모델과의 속도를 비교한 것입니다. 표를 보면 주어진 FLOPS에서 ShuffleNet V2가 다른 모델보다 큰 차이로 속도가 앞선 것을 볼 수 있는데, 이는 가이드라인을 준수한 효율적인 설계 덕분이라 생각됩니다.
홍머스 정리
- FLOPS 이외에 직접적인 지표인 속도를 고려해야
- Memory access count (MAC)
참조
'Machine Learning Models > Covolutions' 카테고리의 다른 글
| EfficientNet (0) | 2021.03.10 |
|---|---|
| DenseNet (0) | 2021.03.03 |
| NASNet (0) | 2021.03.02 |
| Xception (0) | 2021.02.28 |
| ShuffleNet (0) | 2021.02.27 |



