최근 인공지능 학계에서 큰 화두가 되고 있는 분야는 바로 AutoML일 것입니다. AutoML이란 딥러닝 architecture를 사람이 직접 설계하는 것이 아닌 machine learning 방법론으로 설계하는 방법론으로 여러 방법론이 있습니다만, 이번 포스트에서는 학습을 통해 최적의 architecture를 찾아가는 architecture search 방법론을 알아볼 계획입니다.
Architecture search에서의 학습은 유전 알고리즘, 강화학습, gradient 방식 등이 주로 사용되며 이번 포스트에서 알아볼 NASNet은 강화학습 기반의 architecture search 방법론입니다.
Neural Architecture Search (NAS)
강화학습으로 최적의 architecture를 찾는 연구는 2017년에 발표된 "Neural Architecture Search with Reinforcement Learning" 논문으로 각 convolution layer의 stride, filter size등을 결정하는 RNN controller와 이 RNN controller로 구성한 모델을 학습시킨 후, validation accuracy를 reward로 하여 RNN controller를 학습시키는 방향으로 이루어져 있습니다.
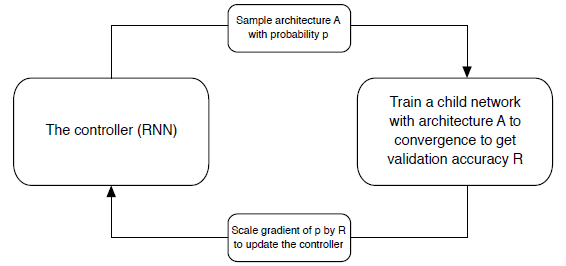
강화학습을 이용해서 훈련을 하는 것은 여러 개의 episode로 이루어진 batch를 통해서 이루어집니다. NAS에서의 episode는 구성한 모델에 대해 학습을 시키고 reward로 사용하기 위한 성능 측정까지 포함합니다. 하나의 episode 데이터를 얻는데 오랜 시간이 걸리니, 최적의 모델을 찾는데 매우 오래 걸리겠죠?
NAS에서는 CIFAR-10에 대한 최적의 모델을 찾기까지 GPU 800대로 한 달의 시간이 소요되었습니다. ResNet보다는 높고 DenseNet과 거의 유사한 성능을 얻었으니 큰 의미가 있지만 지나치게 오래 걸립니다. 또한, CIFAR-10은 32 x 32의 작은 이미지 데이터셋이고 데이터량도 5만 여장으로 매우 작습니다. 이미지 사이즈가 299 x 299 이며 1000개의 class를 가지고 훈련 데이터량도 백만장이 넘는 ImageNet같은 큰 데이터셋에 대해서는 얼마나 더 오래걸릴까요?
NASNet
NASNet의 가장 큰 의미는 ImageNet 같은 큰 데이터에 직접적으로 architecture search하기엔 비용이 너무 크니 CIFAR-10과 같은 작은 데이터셋에 대해 찾은 최적의 모델 (proxy model)을 찾고 큰 데이터셋에 대해 scalable하게 적용하여 높은 성능을 보인 것입니다.
기존 NAS와의 가장 큰 차이점은 새로운 search space의 제안입니다. NAS의 경우 network를 구성하는 각 layer에 대해 최적의 unit을 탐색하기에 탐색 공간이 너무 크고 규칙성이 없을 정도로 매 layer마다 각각 다른 다른 모양의 convolution 파라미터, stride, skip connection 등을 사용합니다.
NASNet의 경우에는 각 layer가 아닌 convolution cell을 탐색하고 이를 조합하여 network를 구성합니다. 이는 최신 CNN 모델이 하나의 블락이나 모듈이 여러 번 반복되는 형태에서 영감을 얻었다고 하는데요. RNN controller로 하여금 generic한 convolution cell을 구성하고 이를 여러 번 쌓는 형태로 모델을 구성하게 됩니다.
이러한 방법론을 통해 search space를 획기적으로 줄이고 작은 데이터셋에 대한 최적의 모델을 큰 데이터셋에 scale-up이 가능함을 보였고 500개의 GPU로 4일의 시간이 소요되었다고 합니다.
구성 요소
NASNet은 RNN controller로 convolution cell을 구성하고 이 cell을 여러 번 쌓아 전체 network를 구성합니다. 이 cell은 $B$개의 block으로 구성되어 있고 각각의 block은 5개의 구성 요소로 이루어져 있습니다.
Block
Block은 2개의 연산을 수행하여 하나의 feature map을 생성하는 역할을 하며 RNN controller의 block 예측 모델에는 5개의 block 구성 요소 예측이 들어 있습니다. 각 5개의 step마다 분류를 위한 독립적인 softmax layer가 들어가고 2개의 hidden state, 2개의 operation, 1개의 combine 방법을 선택하게 됩니다.
간단히 설명하면 밑 그림의 2개의 회색을 입력으로 해서 노란색의 어떠한 연산을 수행하고 마지막으로 2개의 입력을 합치는 연산까지 총 5개의 요소로 구성되어 있습니다. 결정 순서는 다음과 같습니다.

-
2개의 hidden state input을 결정합니다. 여기서 hidden state는 network의 중간 feature map이라 이해하시면 됩니다. Hidden state input은 해당 block이 포함되어 있는 convolution cell의 input $h_i$나 전 단계 convolution cell의 input $h_{i-1}$, 또는 이전 block의 hidden state input을 사용합니다.
-
선택할 hidden state input에 적용할 operation을 선택합니다. 지원하는 operation의 종류는 다음과 같습니다.

-
선택한 operation의 결과물을 어떻게 합쳐 하나의 feature map으로 만들 것인지 결정합니다. 여기서 도출되는 feature map은 새로운 hidden state가 되겠죠. Combine method는 element-wise add, concatenation 중 하나로 결정됩니다.
이렇게 순차적으로 $B$개의 block을 만들어내면 하나의 convolution cell을 구성하게 됩니다.
Convolution Cell
Convolution cell은 NASNet의 기본 구성 요소입니다. 다음 그림과 같이 여러 개의 block을 쌓아 하나의 cell을 구성합니다. 주목할 점은 매 block의 결과물이 새로운 hidden state로 추가된다는 점입니다.

일반적인 CNN은 이미지의 입력 사이즈를 줄이는 down sampling을 갖고 있듯이 NASNet에도 어떠한 입력 사이즈에도 scalable한 architecture를 설계하기 위해 다음과 같은 2가지 cell 종류를 설계합니다.
-
Normal Cell: 입력 feature map의 크기와 같은 사이즈를 가지는 feature map을 return합니다. 따라서 convolution의 stride가 고정되어 있습니다.
-
Reduction Cell: 입력 feature map의 크기를 절반으로 줄인 feature map을 return합니다. Reduction cell의 경우 cell input에 적용하는 첫 operation은 stride 2로 고정되고 그 이후 operation은 stride 1이 됩니다.
모델 구성
Normal cell과 Reduction cell은 같은 구조를 가지고 있을 수 있지만 이 2개의 cell을 따로 예측하는게 더 효율이 좋았다고 합니다. 또한, feature map의 사이즈가 절반으로 줄 때, feature dimension을 2배로 늘리는 일반적인 룰을 사용했습니다. 또한, cell의 반복 횟수와 처음 convolution parameter의 파라미터는 따로 학습하지 않고 해당 데이터셋에 대해 각각 정했습니다.
전체 network를 구성하는 방법은 다음과 같습니다.
-
RNN controller는 Normal cell과 Reduction cell 2개의 cell을 동시에 예측합니다. 각 cell은 $B$개의 block으로 구성되어 있고 ($B=5$), 각 block은 5개의 구성 요소를 가지니 RNN controller는 총 $2\times 5B$개의 예측을 하게 됩니다.
-
RNN controller를 통해 구성한 각각의 cell을 구성하고 이 cell을 밑의 그림과 같이 구성하여 architecture를 구성합니다.
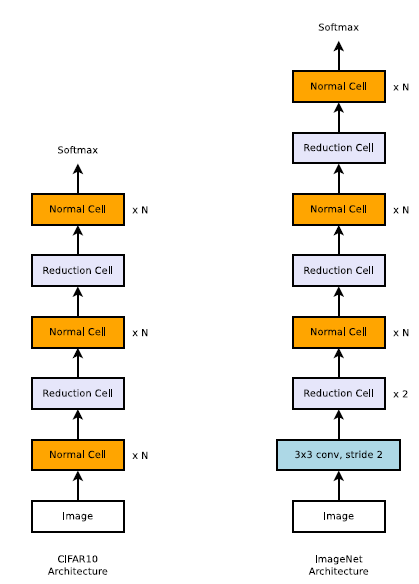
밑의 그림은 CIFAR-10과 ImageNet에 대한 network의 구성도입니다. ImageNet의 이미지 사이즈가 CIFAR에 비해 훨씬 크니 더 많은 Reduction cell이 있는 것을 볼 수 있습니다.
훈련
구성한 architecture에 대해 training data에 대해 학습을 시키고 validation accuracy를 reward로 하여 강화학습을 수행합니다. 즉, 훈련시킬 대상은 RNN controller의 파라미터가 되겠죠.
RNN controller는 100개의 hidden state, 1개의 층으로 구성된 LSTM으로 $2\times 5B$개의 softmax 예측을 수행하게 됩니다. 각 step의 결합확률을 어떠한 모델을 구성할 확률로 정의되고 이는 RNN controller의 gradient를 계산하기 위해 사용됩니다. 이 gradient는 validation accuracy에 의해 scale되는 일반적인 강화학습의 방법론으로 학습됩니다. REINFORCEMENT rule을 사용한 NAS에서와 달리 NASNet은 훈련이 더 안정적인 PPO (Proximal Policy Optimization) 방법을 사용했습니다.
NASNet의 훈련은 500개의 gpu로 이루어진 분산환경에서 수행합니다. 각 gpu가 동시에 각 모델을 훈련시켜 validation accuracy 묶음을 얻고 RNN controller을 업데이트하기 위한 batch를 구성합니다. 이때, minibatch로는 20개의 architecture를 사용했으며, 훈련 후에는 성능이 좋은 250개의 architecture를 뽑아 훈련을 시켜 best architecture를 도출했다고 합니다.
마지막으로 모델 구성 시 dropout과 비슷한 ScheduledDropPath 방법을 사용했습니다. 이것은 dropout을 cell 구성에 적용시킨 것과 비슷한데, cell의 임의의 연산을 특정 확률로 지운 상태로 학습하고 test시에 이 확률만큼 scale 보정하는 방식으로 훈련시키는 것입니다. 특히 Scheduled라는 말에서 볼 수 있듯이 이 특정 확률을 훈련 시간에 선형적으로 증가시키는 것이 실험상 좋은 결과를 얻을 수 있었다 합니다.
EXPERIMENT

위의 그림은 NASNet의 가장 좋은 performance를 보이는 cell입니다. Convolution의 경우 거의 depthwise separable convolution (sep)이 선택된 것을 볼 수 있고 마지막 combine연산은 모두 element-wise add 연산이 선택된 것을 볼 수 있습니다.
Results on CIFAR-10 Image Classification
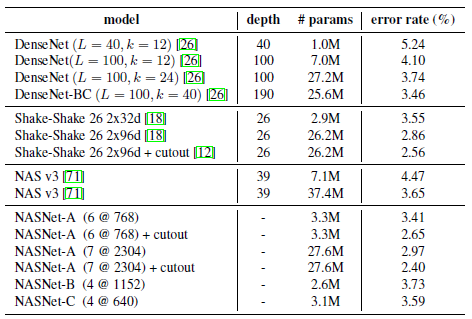
NASNet의 파라미터 수를 조절해가며 기존 방법론과 비교했을 때, 더 좋은 성능을 낸 것을 확인할 수 있습니다. 실험은 5번 실행해서 평균을 내었다고 합니다.
Results on ImageNet Image Classification
CIFAR-10으로 찾은 최적의 architecture를 ImageNet 데이터에 적용하면 어떻게 될까요? 적용 시에는 맨 마지막 softmax 단의 출력 개수가 1000개로 바뀌고 맨 처음 3 x 3 convolution (stride 2) 가 적용된 것을 제외하면 다른 것이 없습니다.

비슷한 파라미터와 연산 수를 가짐에도 제일 높은 정확도를 달성한 것을 볼 수 있습니다. 사람이 직접 설계한 다른 모델에 비해서 강화학습으로 찾은 최적의 모델이 심지어 ImageNet 데이터셋에 대해서 찾은 것이 아닌 간단한 CIFAR-10에 대해서 찾은 모델이 제일 높은 성능을 보였습니다.
Efficiency of architecture search methods
이 실험은 강화학습과 random search로 search space를 탐색했을 때의 효율성을 비교하는 것입니다. 즉 무작위로 최적의 모델을 찾았을 때보다 강화학습이 얼마나 효과적인지를 알고 싶은 것입니다. 여기서의 random search는 RNN controller의 softmax 단의 확률로 구성 요소를 뽑는 것이 아닌 uniform distribution에서 구성 요소를 뽑는 것을 말합니다.
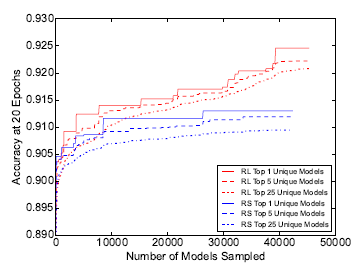
당연하곗지만 강화학습으로 찾은 최적의 모델이 성능이 더 좋습니다. 하지만 무작위 탐색 방법으로 찾은 모델도 생각보다 성능이 괜찮습니다. 논문에서는 오히려 NASNet의 search space가 잘 구성되었다 주장합니다.
홍머스 정리
- 2개의 hidden state + 2개의 operation + 1개의 combine -> cell
- 여러 개의 cell을 쌓아 network 구성
- 오래 걸리긴 하지만 딥러닝이 architecture를 직접 설계할 수 있고 결과가 좋은 것에 큰 의미가 있음.
참조
'Machine Learning Models > Covolutions' 카테고리의 다른 글
| EfficientNet (0) | 2021.03.10 |
|---|---|
| DenseNet (0) | 2021.03.03 |
| Xception (0) | 2021.02.28 |
| ShuffleNet V2 (0) | 2021.02.27 |
| ShuffleNet (0) | 2021.02.27 |



