딥러닝 모델은 여러 분야에서 기존의 방법보다 강력한 성능을 보이지만 수많은 비선형의 조합으로 이루어져 왜 잘되는지를 설명하기가 쉽지 않아 보통 black-box 함수로 불리웁니다. 의사 결정 시에는 딥러닝 모델의 결과를 무조건적으로 신뢰하는 것이 아니라 왜 그런 결과를 나타내는지에 대한 설명이 판단 근거로 필요하기 때문에 explainable AI (XAI) 분야에 대한 관심이 점점 높아지고 있는 상황입니다. 예를 들어 이미지의 어떤 부분을 보고 특정한 클래스를 예측했는지 설명이 필요하다는 것이죠.
이 논문은 딥러닝 모델, black-box 함수 $f$의 입출력 관계를 해석하는 방법으로 다음 그림처럼 classification 에서 이미지의 어떤 부분이 $f$의 결과에 가장 큰 영향을 미치는지 설명합니다. 즉, 원래 이미지의 입력이 출력에 가장 안좋은 방향으로 영향을 미치는 mask를 (explaination) 얻는 것이 이 논문의 목표입니다.

Explaining black boxes with meta-learning
What is explanations ?
Black-box 함수 $f$에서의 설명 (explanation)은 어떠한 입력에 관한 $f$의 출력을 결정하는 규칙이라 볼 수 있습니다. 특정 클래스를 예측하는 $f$의 규칙을 $Q(x;f)$라 했을 때, explanation의 신뢰도를 $L=E[1-\delta_{Q(x;f)}]$ 로 측정할 수 있습니다. 여기서 $\delta_Q$는 $Q$가 일어났다는 indicator 함수이고 $L$은 단순히 예측 오차라 볼 수 있습니다. 결과적으로 밑의 수식처럼 모든 규칙의 집합에서 $\mathcal{Q}$, 머신러닝 알고리즘은 $f$에 적용하기 위한 최적의 설명 규칙을 찾는 것이라 볼 수 있습니다. 또한 정규화 항 $\mathcal{R}(Q)$를 통해 일반화가 가능하고 간단히 해석가능한 최적의 $Q$를 찾도록 합니다.

Local explanations
Local explanation $Q(x;f,x_0)$는 $x_0$의 근방 $x$에 대한 $f$의 출력을 예측하는 규칙으로서 $f$가 $x_0$에서 미분 가능하다면 1차 테일러 방식으로 다음과 같이 표현 가능합니다.

이 수식을 통해 기존에 많이 쓰이던 saliency map을 표현할 수 있습니다. 기울기 $\nabla f(x_0)$ 를 통해 큰 기울기를 가진 픽셀이 출력에 큰 영향을 미치는 것으로 판단하는 것이죠. 하지만 간단한 선형 classifier $f(x)=<w,x>+b$에서는 $x-x_0$의 변화가 임의의 방향에서도 $w$로 일정하기 때문에 기울기가 $w$로 일정합니다. Neural networks는 기본적으로 비선형이라 이러한 현상이 덜하지만 완전히 없애지는 못해 saliency map이 상대적으로 넓게 분포하게 되어 중요한 부분을 제대로 찾지 못하는 문제가 있습니다.

논문은 saliency가 $f$의 출력에 큰 영향을 미치는 입력을 찾는다는 점에 착안에 $x_0$에서 가장 중요한 부분을 마스크를 통해 지워 perturb한 $x$를 얻는 방식을 고안합니다. 즉, 이러한 방법을 통해 얻은 마스크로 $f$가 찾은 규칙을 해석하면서 동시에 saliency map을 얻겠다는 것이죠.
Saliency
Meaningful image perturbations
Saliency의 목적은 이미지 $x_0$에서 어떠한 부분이 $f(x_0)$의 결과를 산출하는지 알아내는 것입니다. 이를 위해 $x_0$에서 이미지의 여러 지역을 지워가면서 $x$를 생성하고 $f(x)$를 관측합니다. 즉, $x_0$의 perturb 된 $x$를 통해 local explanation 과 같이 $f$와 $x_0$의 관계를 설명하고 싶은 것이죠.
그렇다면 지운다는 것은 어떤 것일까요? 의미있는 perturbation이 되고 local explanation 처럼 근방에 있는 $x$를 생성하기 위해 $[0,1]$의 값을 가진 마스크 $m$과 각 픽셀 $u$에 대해 이미지의 특정 지역 $R$을 다음과 같이 상수, 노이즈 삽입, blurring을 수행합니다.

$\mu_0$는 이미지의 평균 값이고 $\nu(u)$는 i.i.d Gaussian noise, $g_\sigma$는 Gaussian blur kernel 입니다.
Deletion
정리하면 이미지 $x_0$의 compact한 삭제로 black-box $f$의 행동을 설명하는 것입니다. 다음 수식으로 $f$의 예측력이 심각하게 감소하는 ($f(\Phi(x_0;m)) << f(x_0)$) 가장 작은 deletion mask $m$를 찾습니다.
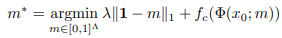
첫 번째 항의 $\lambda$를 통해서 $x_0$을 최소한으로 삭제할 수 있도록 합니다. 위의 perturbation 수식에서 볼 수 있듯이 $m$은 $x_0$에 곱해지므로 1에 가까운 값이 $m$에 많아야 작은 마스크를 만들 수 있습니다. 결과적으로 $f$가 이미지를 제대로 인식할 수 있는 최소한의 evidence를 $m$을 통해 제거하겠다는 겁니다.
Dealing with artifacts
하지만 위의 최적화 수식은 단순한 이미지 왜곡에 심각한 영향을 받습니다. Neural networks 특성 상 이미지에 간단한 왜곡이 존재할 때 잘못된 출력을 내는 경우가 많은데 이로 인해 $x_0$에 대한 $f$를 제대로 설명하지 못하는 $m$을 얻을 수 있다는 것이죠.
밑에서 오른쪽 그림에서 볼 수 있듯이 이미지의 간단한 왜곡을 유발한 perturbation으로 $f$가 전혀 예측을 못하면서 마스크가 제대로 형성되지 않은 것을 볼 수 있습니다. 즉, 마스크가 $f$가 예측을 제대로 못하도록 단순한 artifact만 학습한다는 것이죠. 특히, 아랫줄 그림에서 볼 수 있듯이 노이즈 삽입과 상수의 perturbations 에서 더 심하게 나타나는 것을 볼 수 있습니다.

이 현상을 해결하기 위해서 논문에서는 두 가지 방법을 제안합니다. 첫 번째는 일반화가 가능한 충분한 explanation을 위해 훈련 시 매 iteration 마다 작은 랜덤 노이즈를 주입하는 것입니다. 두 번째는 마스크가 artifact 가 아닌 자연스러운 perturbation 에 대응하도록 사이즈가 작은 마스크에 대해 total-variation 을 적용하고 upsampling 합니다. 최종적은 목적 함수는 다음과 같이 됩니다.

첫 번째 방법은 마지막 항의 $\tau$로 반영되었습니다. (논문에서 잘못 표기된 것 같습니다. 랜덤 노이즈는 마스크에 적용됩니다) 두 번째 방법은 두번째 항의 total-variation norm으로 적용되었습니다. Total-variation은 일반적으로 이미지 denoising에 쓰이는 전통적인 방법으로 인접한 픽셀의 차이를 줄이는 정규화 항으로 작용합니다. 또한, 이미지 전체에 적용하기 위한 마스크 $M$은 작은 사이즈의 $m$으로부터 bilinear upsampling을 통해 얻어집니다. (논문에서는 Gaussian kernel 로 upsampling 합니다)
Implementation details
위에 언급한 문제로 구현에서는 blur perturbation 만 사용되었습니다. 작은 사이즈의 $m$은 모두 1의 값을 가진 $28\times 28$ 초기화되고 매 iteration마다 랜덤 노이즈가 더해지면서 입력 이미지 크기에 맞게 8배 upsampling 됩니다.
Experiment
Interpretability
밑 그림에서 본 논문의 방법인 mask 열의 결과가 다른 방법의 결과보다 훨씬 설명력 있음을 볼 수 있습니다. 특히, 위에서 언급했던 것처럼 gradient 방식은 넓게 펴지면서 이미지의 중요하지 않은 부분을 가리킵니다. 특히, 7번째 줄의 CD player에서는 본 논문의 방법만이 정확히 중요한 부분을 포착한 것을 볼 수 있습니다.

또한, 다른 방법 (contrast-excitation)과의 quantitative한 비교를 위해 각 방법이 도출해낸 마스크가 얼마나 출력 결과를 억제하는지 다음과 같이 확인합니다. 두 번째 줄의 pickup truck의 경우 논문의 방법이 도출해낸 마스크를 커버하는 박스에 대해 perturbation을 주었을 때, constrast-excitation 방법의 박스에 perturbation을 주었을 때보다 출력 스코어가 굉장히 낮아짐을 확인할 수 있습니다.

또한, 첫 번째 초콜릿 소스에서 마스크는 초콜릿이 담긴 병보다 숟가락에 더 포커싱을 두었고 실제 box perturbation의 결과 숟가락 부분에 perturbation을 취했을 경우 출력 스코어가 더 낮아집니다. 이는 모델이 학습할 때, 초콜릿 소스가 병보다 숟가락에 담긴 사진을 더 많이 접했다고 판단할 수 있습니다. 즉, 이 방법을 통해서 사람의 직관과 잘못된 모델의 행동을 설명할 수 있다는 것이죠.
Deletion region representativeness
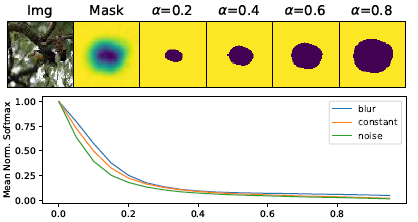
Learned mask가 artifact (왜곡) 에 강건한지 확인하기 위해 마스크를 blurring하고 $\alpha$를 임계치로 하여 $\alpha$보다 작은 값을 0으로 만들어 3가지 perturbation에 대한 성능 추이를 확인합니다. 밑의 그림에서 볼 수 있듯이 $\alpha$가 커질 수록 성능이 급격히 감소하는 모습을 볼 수 있으며, 이는 다양한 perturbation에도 mask가 제대로 학습되었음을 알 수 있습니다.
Minimality of deletions
Mask가 최소한의 지역을 잡는지 확인하기 위해 $h\in[0:0.1,:1]$ 에 대해 임계치를 적용한 후 각 마스크에 대한 tight한 bounding box를 잡습니다. 그후 이미지의 bounding box 부분을 blur한 후 각각에 대해 출력 스코어가 얼마나 감소되는지 확인합니다. 다른 baseline 방법에 대해서도 똑같이 적용합니다. 밑의 그림에서 볼 수 있듯이 논문의 방법이 가장 작은 bounding box를 생성하면서도 목표한 출력 스코어 감소를 이룬 것을 볼 수 있습니다.

Testing hypotheses: animal part of saliency
동물들에 대해서는 동물의 발보다 얼굴이 좀 더 영향력이 크다고 가정하고 mask를 통해 강도를 확인합니다. ImageNet 데이터셋에는 동물의 keypoint인 눈과 발의 위치가 기록된 데이터가 존재하고 이를 통해 keypoint 을 포함하는 $5\times 5$ 윈도우 안의 마스크 강도를 측정합니다. 측정 결과 가정한 대로 눈 부분의 마스크 강도가 더 낮게 나왔으며, 이를 통해 동물 구분에서는 발보다 눈이 더 saliency 하다고 판단할 수 있습니다.

Adversarial defense
Adversarial example은 이미지가 최대한 잘못 분류되도록 노이즈가 삽입된 이미지를 말합니다. 논문에서는 본래 이미지와 adversarial example에 대해서 마스크를 뽑아낸 후 이를 통해 본래 이미지와 adversarial 이미지를 분류 성능을 측정합니다. 측정 결과 다른 방법에 비해 더 좋은 성능을 보였습니다. 또한 놀랍게도 adversarial example에 대해 뽑아낸 마스크를 다시 adversarial example에 적용한 결과 본래의 라벨로 다시 잘 분류되었다고 합니다.

홍머스 정리
- 최종 결과는 간단하나 이를 유도하기 위한 설명이 살짝 난해
- 구현은 간단
참조
'Machine Learning Models > Techniques' 카테고리의 다른 글
| Label Smoothing (0) | 2021.06.15 |
|---|---|
| CutMix (0) | 2021.06.10 |
| Mish (0) | 2021.06.06 |
| Learning Deep Features for Discriminative Localization (CAM) (0) | 2021.05.08 |
| FLOPS (FLoating point OPerationS) - 플롭스 (2) | 2021.02.25 |


