Multi-class 분류를 위한 cross entropy loss 에서 목적함수의 타겟으로 사용되는 라벨은 일반적으로 정확히 하나의 클래스만 명확히 표현하는 (one-hot vector) hard 라벨이 사용됩니다. Label smoothing 기법은 한 클래스가 전체를 모두 차지하는 hard 라벨을 정답 클래스의 비중을 약간 줄이고 나머지 클래스의 비중을 늘리는 soft 라벨로 변환하는 기법인데요, 처음에는 Inception 구조의 성능을 높이고자 도입되었고 간단한 정규화 방법으로 image classification, speech recognition, machine translation 분야에 Table 1에서 처럼 적극적으로 사용되고 있습니다.

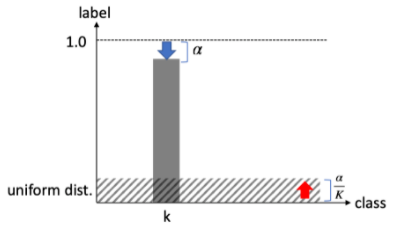
$K$개의 클래스에 대해서 라벨을 얼마만큼 부드럽게 할 것인지 정하는 smoothing 파라미터를 $\alpha$라 할 때, $k$ 클래스를 나타내는 hard 라벨 $y_k$에 대해 label smoothing 을 거친 soft 라벨 $y_k^{LS}$는 다음과 같이 hard 타겟과 나머지 라벨의 uniform 분포의 weighted 평균으로 정의되고 각 라벨의 총합은 1로 유지됩니다. 예를 들어 $K=4$ 이고 $y_k=[0,1,0,0]$에 대해 $\alpha=0.1$ 이면 $y_k^{LS}=[0.025, 0.925, 0.025, 0.025]$가 됩니다.
$y_k^{LS}=y_k (1-\alpha) + \alpha / K$
즉, 밑의 그림과 같이 정답 클래스 $k$가 차지하는 비중을 줄이면서 나머지 클래스에 대해서 $\alpha/K$만큼의 uniform 분포를 줌으로서 발생할 수 있는 라벨 노이즈에 대해 사전 분포를 적용했다고 생각할 수 있습니다.
Label smoothing
Effects
Multi-class 분류를 위해서 deep neural networks 를 사용할 때 직전 layer (penultimate layer) 에서의 출력 $x$와 마지막 layer 파라미터와의 곱인 logit $x^T W$을 확률 분포로 만들어주기 위해 softmax 함수를 거칩니다. $p_k$를 $k$ 클래스에 할당될 likelihood라 했을 때, $p_k = \frac{e^{x^T w_k}}{\sum_i e^{x^T w_i}}$ 와 같이 표현할 수 있고 훈련은 cross entropy loss $H(y, p)=\sum_k^K -y_k log (p_k)$ 를 사용합니다. 이때, $y_k$ 대신 $y_k^{LS}$를 대입하여 label smoothing 효과를 적용하는 것이죠. 그렇다면 label smoothing 기법을 적용함으로써 어떤 현상이 발생할까요?
Hard 라벨 사용시 정답인 $k$ 클래스에만 모든 확률 1을 부여하기 때문에 cross entropy loss 최소화를 위하여 $k$ 번째 logit $x^T w_k$가 다른 클래스의 logit 에 비해 매우 커지게 됩니다. 특히, softmax 함수는 exponential 함수로 구성되어 있고 절대 0이나 1이 될 수 없다보니 그러한 현상이 더욱 심해지죠. 하지만 label smoothing 을 통한 soft 라벨은 정답이 아닌 클래스에 대해서도 작지만 일정 확률을 가지고 있으니 정답 클래스의 logit 만 지나치게 비대해지는 현상이 매우 완화됩니다.
또한, 정답이 아닌 클래스에 대해서도 균일한 포션만큼 fitting 을 하게 되므로 정답 클래스의 logit 을 정확한 분류를 위해 크게 하면서 정답이 아닌 클래스의 logit 과의 거리를 일정하게 하는 효과가 있습니다. $k$ 클래스에 대한 logit 은 $x$와 $k$ 클래스를 나타내는 template 벡터 $w_k$ 사이의 Euclidean 거리를 줄이는 과정으로 볼 수 있는데, $\Vert x-w_k\Vert^2=x^T x -2x^T w_k + w_k^T w_k$ 이고 $x^T x$는 softmax 함수 과정에서 제거되고 $w_k^T w_k$는 보통 상수이므로 무시할 수 있습니다. 즉, label smoothing 기법은 penultimate layer 출력 $x$와 $w_k$를 가깝게 하면서 정답이 아닌 클래스들은 작은 같은 확률을 가지고 있으므로 그 클래스들의 template 벡터와 같은 거리를 가지도록 한다는 것이죠.
Penultimate layer representations
이러한 효과를 관찰하기 위해 1) 3가지 클래스를 뽑고, 2) 3가지 클래스에 대한 3개의 template 벡터가 구성하는 hyperplane 의 orthonormal basis 를 찾고, 3) $x$를 2번 과정에서 찾은 orthonormal basis 와 내적하여 hyperplane 에 사영하는 과정을 통해 $x$의 2차원적 분포를 관찰합니다. (이때 $x\in R^d$라면 2번 과정에서의 orthonormal basis 는 2개의 $d$ 차원 벡터로 구성되어 있습니다.)
Figure 1은 데이터셋, 모델 구조를 달리하면서 label smoothing 적용 여부에 따른 $x$의 분포 그림입니다. 먼저 첫 번째 줄은 CIFAR-10 에서 "airplane" / "automobile" / "bird" 클래스에 대한 결과로 label smoothing 기법을 적용하지 않았을 때 $x$가 넓게 퍼져있지만 lable smoothing 적용 후에는 각 클래스에 대한 군집이 더 컴팩트해지고 다른 클래스와의 거리가 일정하므로 삼각형을 구성합니다. 두 번째 줄은 CIFAR-100/ResNet-56 에 대한 결과로 첫 번째 줄과 결과가 비슷합니다. 또한, label smoothing 효과로 인해 정답이 아닌 클래스 logit 간의 거리도 어느 정도 일정하게 유지되어야 하기 때문에 label smoothing 적용시 분포 상의 크기가 상대적으로 더 작은 것을 볼 수 있습니다.
Figure 1의 마지막 줄은 Inception-v4/ImageNet 에 대한 결과로서 3개 중에 2개를 매우 비슷한 클래스로 선택한 경우입니다. ('toy poodle" / "miniature poodle") Hard 라벨에 대해서는 비슷한 클래스에 속한 샘플에 대해서는 거의 구분되지 않고 섞이는 것을 볼 수 있지만 label smoothing 적용 시 다른 클래스에 대해 같은 거리를 유지하기 위해 아크 형태를 보이게 됩니다. 결과적으로 hard 라벨을 통한 학습은 정답 클래스의 logit 만 매우 크게하고 정답이 아닌 클래스 logit 에 대해서는 강제하는 효과가 없지만 soft 라벨은 다른 클래스에 대해서 작지만 같은 확률을 부여하기 때문에 정답이 아닌 클래스들과 비슷한 거리를 유지하도록 강제하는 효과가 있습니다.

Calibration
일반적으로 deep neural networks 를 통한 multi-class 분류는 over-confidence 합니다. 즉, 출력 확률의 결과가 0.8이면 정확도의 기대값도 0.8이어야 하지만 일반적으로 정확도는 모델이 가진 confidence (출력 확률) 보다 낮다는 것이죠. 이 부분은 딥러닝 모델의 신뢰도와 관련된 부분으로 딥러닝 모델이 자신의 결과를 과잉신뢰한다면 중요한 판단을 해야하는 경우에 대해서 높은 예측 확률로 틀려버리는 치명적인 문제를 낳을 수 있습니다. 즉, 무엇인가를 예측할 확률과 정확도가 일치시키는 calibration 과정이 필요하고 가장 대표적인 방법으로 softmax 함수의 logit 부분에 scaling temperature $T$를 삽입하는 방법이 있습니다.
$p_k = \frac{e^{x^T w_k / T}}{\sum_i e^{x^T w_i / T}}$
좋은 Calibration 은 Figure 2의 reliability diagram 에서의 점선처럼 confidence 가 정확도가 일치하는 경우일 겁니다. 즉, 가장 이상적인 경우는 softmax 확률의 최대값이 그대로 정확도가 되는 경우인데 over-confident 하다면 logit 부분에 $T$를 나누어줌으로서 그 확률을 줄여줌으로서 확률 분포가 uniform 분포에 살짝 가까워지지만 각 클래 스 별 확률값 순서를 유지하면서 calibration 을 하겠다는 것이죠.

Figure 2에서 보다시피 $\alpha$를 통한 label smoothing 또한 calibration 효과를 거둘 수 있습니다. 우측 아래에 있는 직선은 전형적인 over-confident 한 모델로 label smoothing / temperature scaling 모두 적용하지 않은 경우입니다. 이에반해 label smoothing 을 살짝 적용하거나 temperature scaling 을 적용했을 때 이상적인 점선에 가까워진 것을 볼 수 있습니다. 특히, label smoothing 경우는 Figure 1에서처럼 훈련 데이터를 각 클래스에 맞게 군집화하는 경향이 있는데도 calibration 효과가 있다는 것입니다. Figure 1의 첫 번째 줄 맨 오른쪽 결과를 보면 훈련 데이터셋에 대해서는 매우 잘 뭉쳣지만 validation 데이터셋에 대해서는 각 클래스 중심으로 어느 정도 퍼져있는 것을 볼 수 있고 이는 각 예측에 대한 confidence 가 넓게 퍼져있다는 것을 의미합니다.
Pytorch 구현
Pytorch 의 "torch.nn.CrossEntropyLoss()" 함수는 forward 진행 시 타겟 라벨은 클래스 번호를 나타내는 정수만을 허용하여 soft 라벨을 적용하기 위해서는 직접 구현해주어야 합니다. 다음과 같이 torch.gather 함수를 이용하여 정답 클래스에 대한 loss 와 uniform 분포로 smoothing 을 적용한 다른 클래스에 대한 loss 로 나누어 적용할 수 있습니다.
class LabelSmoothingCrossEntropy(nn.Module):
def __init__(self):
super(LabelSmoothingCrossEntropy, self).__init__()
def forward(self, x, target, smoothing=0.1):
confidence = 1. - smoothing
logprobs = F.log_softmax(x, dim=-1)
nll_loss = -logprobs.gather(dim=-1, index=target.unsqueeze(1))
nll_loss = nll_loss.squeeze(1)
smooth_loss = -logprobs.mean(dim=-1)
loss = confidence * nll_loss + smoothing * smooth_loss
return loss.mean()혹은, 다음과 같이 간단하게 구현할 수 있습니다.
def softXEnt(input, target):
logprobs = F.log_softmax(input, dim=-1)
return - (target*logprobs).sum() / input.shape[0]
참조
'Machine Learning Models > Techniques' 카테고리의 다른 글
| Smooth L1 Loss vs Huber Loss (0) | 2022.10.12 |
|---|---|
| GELU (Gaussian Error Linear Unit) (0) | 2021.06.18 |
| CutMix (0) | 2021.06.10 |
| Mish (0) | 2021.06.06 |
| Learning Deep Features for Discriminative Localization (CAM) (0) | 2021.05.08 |



