시계열 데이터를 처리하기 위해서는 데이터를 stationary 하게 만든 이후에 AR, MA, ARMA, ARIMA 모델 등을 적용해야 합니다. 지난 포스트에서 알아봤듯이 stationary 하기 위해서는 시계열 데이터의 평균, 분산이 시간에 따라 일정해야 하고 래그 $h$에 따른 공분산이 일정해야 합니다. Stationary를 그림으로 그려서 판단할 수 있지만 통계적인 정량적 방법으로 검증할 수 있는 방법이 바로 Augmented Dickey-Fuller Test (ADF Test) 입니다.
먼저 Dickey-Fuller Test는 1979년에 David Dickey와 Wayne Fuller에 의해 개발된 autoregressive 모델의 단위근 (unitroot) 통계 검정 방법으로 대표적인 stationary 검증 방법입니다. 우리가 지난 포스트에서 AR(1) 모델의 계수 $\phi$의 절대값이 1보다 작아야 stationary 하다는 것을 알아보았고, Dickey-Fuller Test도 여기에서부터 출발합니다.
$X_t$ = $\alpha X_{t-1} + a_t$
위의 AR(1) 수식에서 $\alpha$가 단위근 (1) 일 경우 non-stationary 합니다. Dickey-Fuller Test는 다음 수식에서 귀무가설 ($H_0: \alpha=1$) 을 통계적으로 검정하는 방법입니다.
$y_t = c + \beta t + \alpha y_{t-1} + \phi \nabla y_{t-1} + e_t$
$c$는 시계열 데이터의 레벨, $\beta$는 시계열 데이터의 추세항을 나타내며, 각 파라미터를 regression으로 추정하여 $\alpha$가 단위근을 가질 확률이 얼마나 되는지 검정하는 것이죠. $\alpha=1$이라면 단위근을 가지는 것이므로 stationary 하지 않다고 판단하는 겁니다.
AR(1)에서 $\nabla y_{t-1}$을 추가해서 검정하는 이유는 무엇일까요? 직관적으로 생각해보면 stationary 하다면 평균이 상수이기 때문에 평균으로 가고자 하는 경향이 있고 이는 전 시점의 차분 $\nabla y_{t-1}$에 대해 현재 시점의 값을 반대 방향으로 가고자 할 겁니다. 따라서 $y_{t-1}$의 값의 영향력이 약해지겠죠. 반대로 stationary 하지 않다면 $y_{t-1}$항의 영향력이 가지게 되어 $\alpha$가 1이 될 확률이 높아집니다.
Augmented Dickey-Fuller Test는 Dickey-Fuller Test를 확장하여 $p$ 래그의 차분만큼을 추가하여 기존 test의 검정 능력을 더 강화한 것입니다.
$y_t = c + \beta t + \alpha y_{t-1} + \phi_1 \nabla y_{t-1} + ... +\phi_p \nabla y_{t-p} + e_t$
위의 DF Test에서 $p$ 래그의 차분만큼 항이 추가된 것을 알 수 있고, DF Test와 귀무 가설은 똑같습니다. 즉, $p$ 래그의 차분만큼 수식을 확장하여 $\alpha=1$의 여부를 판단하겠다는 것이죠. 따라서 $t-p$ 시점까지의 차분 경향성을 파악할 수 있으므로 주기를 가진 데이터에 대해서도 확장해서 stationary 여부를 판단할 수 있습니다. 귀무 가설은 단위근이 존재하는 것이므로 ($\alpha=1$) 귀무가설을 기각하기 위해서는 p-value 0.05 (0.01) 보다 낮게 나와야 합니다.
ADF Test를 정리해보면, 차분을 여러 래그에 대해 수행하였을 때 $y_{t-1}$의 계수인 $\alpha$가 1이라면 stationary하지 않다는 것입니다. 반대로 귀무가설이 기각된다면 $\alpha$가 1보다 작게 되는 것이므로 stationary 하다고 판단할 수 있는 것입니다.
Python
파이썬에서는 statsmodel 패키지에서 adfuller 라는 ADF Test를 쉽게 할 수 있는 api를 제공합니다.
from statsmodels.tsa.stattools import adfulleradfuller 함수안에 시계열 데이터를 넣을 경우 1) p-value, 2) test-statistics, 3) critical value, 4) lag, observation 개수를 결과로 얻을 수 있습니다. Critical value는 통계 검정에서 검정 값의 판단 기준으로 작용하는 값으로, 귀무 가설 상태에서 해당 확률 (1%, 5%)이 나오게 되는 값을 의미합니다. 즉, ADF Test의 검정 값이 critical value보다 낮게 되면 귀무 가설 상테에서 확률이 매우 낮은 상태이니 p-value가 낮아 귀무 가설을 기각할 수 있다는 말이 됩니다.
def adf_test(y):
## perform Augmented Dickey Fuller test
print('Results of Augmented Dickey-Fuller test:')
dftest = adfuller(y, autolag='AIC')
dfoutput = pd.Series(dftest[0:4], index=['test statistic', 'p-value', '# of lags', '# of observations'])
for key, value in dftest[4].items():
dfoutput['Critical Value ({})'.format(key)] = valueadfuller 함수의 파라미터는 다음과 같습니다.
| 파라미터 | Description |
| x | 시계열 데이터 |
| maxlag | ADF Test에서 $p$를 지정합니다. 이때, autolag를 None으로 설정해야 maxlag에 지정한 값이 적용됩니다. 지정하지 않을 경우 $12*(nobs/100)^{1/4}$로 결정됩니다. |
| regression | 1. 'c': 추세는 없고 상수항이 존재한다고 가정하며 위 식에서 $c$에 해당합니다. (디폴트) 2. 'nc': 상수항과 추세가 없다고 가정합니다. 위 식에서 $c, \beta$가 0으로 설정됩니다. 3. 'ct': 추세와 상수항이 둘다 존재한다고 가정합니다. 4. 'ctt': 상수항과 일차, 이차 추세가 모두 존재한다고 가정합니다. |
| autolag | ADF Test에서 $p$를 자동으로 지정합니다. 1. 'AIC', 'BIC': AIC나 BIC가 가장 낮게 나오는 $p$를 자동으로 설정하고 autolag를 이렇게 지정하였을 경우 maxlag에서 지정한 값이 무시됩니다. 2. None: maxlag에서 지정한 값이 설정됩니다. 3. 't-stat': maxlag에서 지정한 값부터 regression을 수행하면서 통계 검정 p-value가 5% 미만이 될때의 래그 $p$값으로 설정합니다. |
Example
시계열 데이터에서 많이 사용되는 international-airline-passengers에 대해 살펴보겠습니다.
Raw data

위 시계열 데이터는 추세가 존재하면서 계절성을 가지고 있으므로 stationary하지 않다고 바로 알 수 있습니다. adfuller 함수를 이용해 ADF Test를 수행하면 다음과 같은 결과를 얻을 수 있습니다.
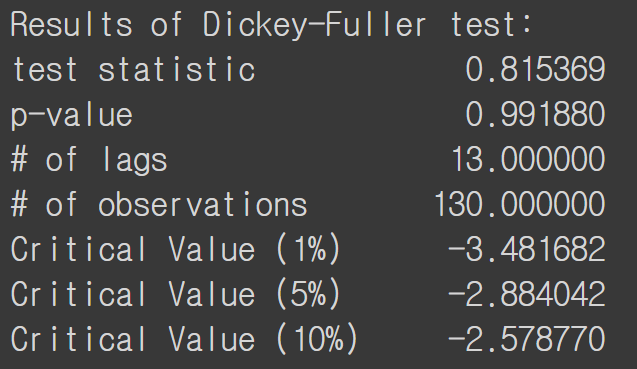
p-value가 매우 높고 test statistics도 매우 높게 나와 귀무가설을 기각할 수 없습니다. 즉, stationary 하지 않습니다. 더 나아가 분산을 줄이기 위해 log transformation을 취한 이후에 ADF Test를 적용해 보겠습니다.
Log transform

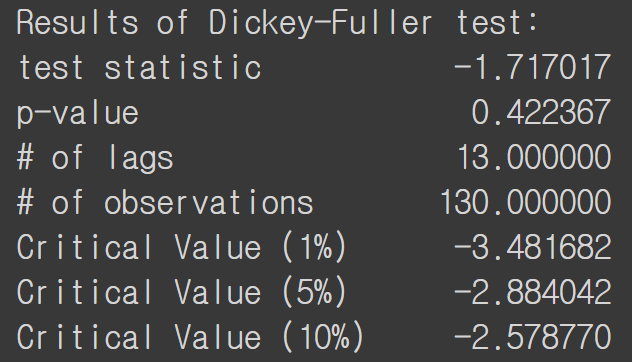
p-value가 낮아지긴 했지만 아직 매우 높고 test statistics도 critical value보다 높으므로 stationary 하지 않습니다. 그렇다면, log transformation을 하고 차분을 한 이후의 ADF Test를 진행해 보겠습니다.
Log transform first-order differencing


아직 stationary라 판단하기는 이르니, log transform을 한 이후에 2차 차분을 수행한 뒤에 ADF Test를 해보겠습니다.
Log transform second-order differencing
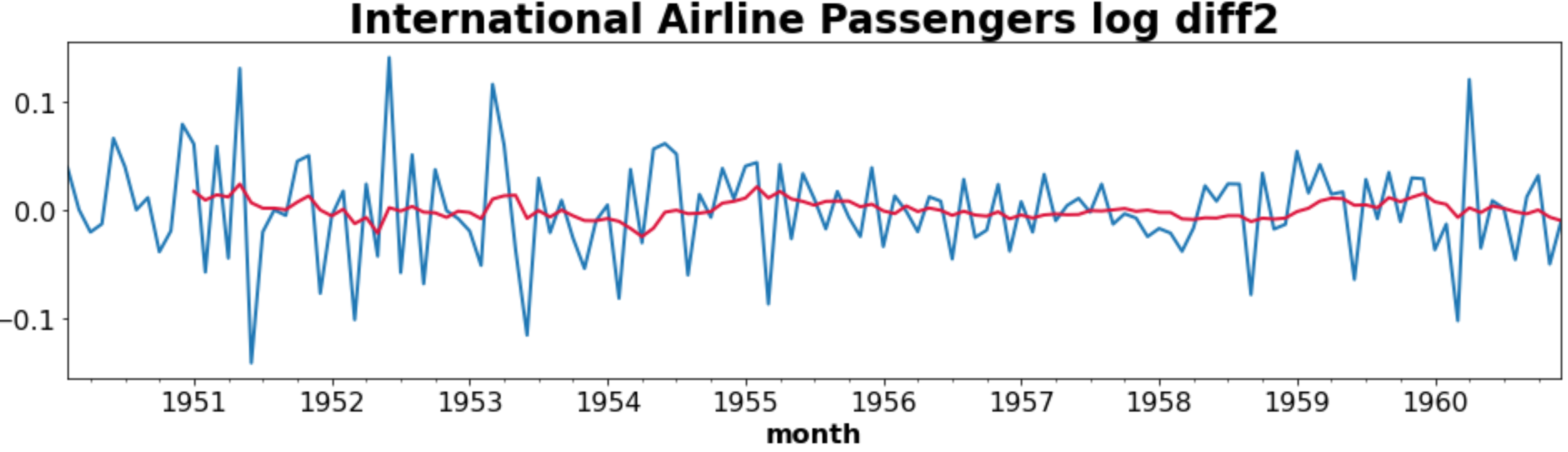
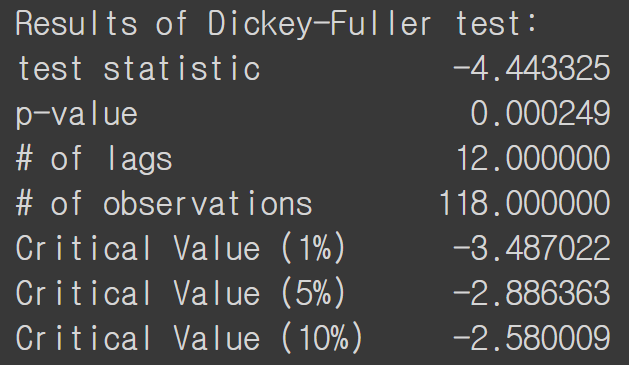
p-value가 0.05 미만이고 test statistics 또한 critical value보다 낮으므로 통계적으로 stationary 하다고 판단할 수 있습니다. ACF, PACF, QQ plot 등으로 정성적으로 판단할 수 있지만 ADF Test를 통해서 통계적으로, 정량적으로 stationary 여부를 파악할 수 있습니다.
주의점
가끔씩 stationary 하지 않아야 하지만 adfuller를 이용하였을 때 stationary 한 결과가 나올 수 있습니다.

위 데이터에 대해서는 주기가 존재하므로 non-stationary 하여야 하지만 ADF Test 결과는 다음과 같이 test-statistics와 p-value가 모두 매우 낮습니다.

이는 ADF Test를 수행할 때, 주기까지의 래그가 반영되지 않은 경우이므로 adfuller의 파라미터를 다음과 같이 조절해주어야 합니다.
def adf_test(y):
## perform Augmented Dickey Fuller test
print('Results of Augmented Dickey-Fuller test:')
dftest = adfuller(y, autolag=None, maxlag=원하는 래그 값)
dfoutput = pd.Series(dftest[0:4], index=['test statistic', 'p-value', '# of lags', '# of observations'])
for key, value in dftest[4].items():
dfoutput['Critical Value ({})'.format(key)] = value
print(dfoutput)
'Machine Learning Tasks > Time Series' 카테고리의 다른 글
| 파이썬에서 SARIMA 실행하기 - SARIMAX (5) | 2021.03.31 |
|---|---|
| Deep State Space Models for Time Series Forecasting (0) | 2021.03.18 |
| Multivariate Time Series (1) - 기본 확률 (0) | 2021.03.13 |
| Exponential Smoothing, CMA, Winter's Method (0) | 2021.03.12 |
| Nonstationary process, ARIMA, SARIMA (0) | 2021.03.11 |


