이전 포스트
[Machine Learning/Unsupervised Learning] - Self-Supervised Learning - SwAV (1)
Experiments
SwAV 의 기본 실험 세팅은 SimCLR 과 거의 비슷합니다. 배치 사이즈는 4096을 사용하고 $\tau=0.1$, $\epsilon=0.05$를 사용합니다. 또한, LARS 옵티마이저를 사용하며 SimCLR 처럼 learning rate를 초반에 4.8로 높게 선택하고 일정 epoch 이후 cosine learning rate decay에 의해 감소시킵니다. 마지막으로 2-layer MLP projection head를 사용합니다.
실험 전체적으로는 ResNet-50 모델을 400 epoch 만큼 훈련시키며 2개의 일반적인 random crop (160), 4개의 추가적인 저해상도 random crop (96), 총 6개의 augmentation을 사용합니다. 또한 code (cluster)를 할당하는 프로토타입의 차원 $K$는 차원에 따른 성능이 거의 없었고 지나치게 증가시키면 Sinkhorn 알고리즘 계산 시간이 성능 이득에 비해 오래 걸리므로 3000으로 설정합니다.

Data augmentation
지난 포스트에서 언급했던 것처럼 SwAV는 2개의 일반적인 rancom crop/resize, $V$개의 저해상도 random crop/resize, 총 $V+2$개의 augmentation을 사용합니다. 먼저 2개의 random crop/resize는 torchvision.transform 모듈의 RandomResizedCrop 함수를 사용하며 가로로 폭이 좁게 $s=(0,14, 1)$로 랜덤하게 crop 한 후 224x224 의 크기로 리사이즈 합니다. $V$개의 추가적인 augmentation은 $s=(0.05,0.14)$로 저해상도 random crop 한 후 96x96의 크기로 리사이즈합니다. 이후 각 augmentation에 랜덤한 horizontla flips/color distortion/Gaussian blur를 적용합니다.

Evaluating the unsupervised features on ImageNet
ResNet-50 모델에 대해 linear evalutaion/semi-supervised 실험을 수행합니다. 먼저 고정된 representation에 적용하는 linear evaluation 에서 SOTA의 성능을 거두었으며, semi-supervised learning 에서 또한 독보적인 성능을 보였습니다. 다른 self-supervised learning 모델과 마찬가지로 SwAV 또한 모델이 커질수록, 오래 훈련할수록 성능이 증가합니다.


특히, 모델의 width를 일정 정수배만큼 곱해 모델의 크기를 증가시킬 경우 R50-w5 케이스에서 78.5%를 기록했습니다.

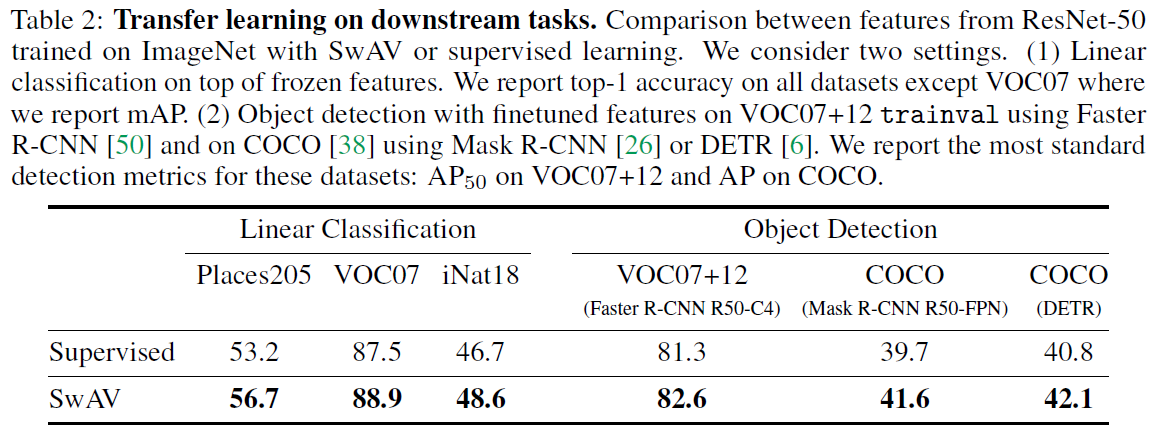
Transferring unsupervised features to downstream tasks
다음으로 ImageNet으로 pretrain 시킨 representation을 이용하여 다른 데이터셋/태스크에 적용하는 transfer learning을 수행합니다. 다른 데이터셋에 linear classification을 적용한 경우 supervised 에 비해서도 높은 성능을 거두었고 object detection task에서도 기존의 supervised를 뛰어넘었습니다.
Training with small batches
256의 작은 배치 사이즈에 대한 성능을 실험합니다. MoCo의 경우 momentum encoder를 위해 65536개의 feature를 저장하고 있어야 하지만 SwAV는 3840개의 feature를 저장합니다. 또한 $V=4$를 사용할 경우 SimCLR/MoCo에 비해 한 epoch가 느리지만 상대적으로 짧은 epoch안에 더 좋은 성능을 얻을 수 있다고 합니다. 특히, MoCov2의 경우에 비해 4배 적은 epoch만에 72% 성능에 도달합니다. 특히, 해상도와 훈련 epoch를 증가시킬 수록 좋은 성능을 얻을 수 있습니다.

Applying the multi-crop strategy to different methods
제안한 multi-crop augmentation으 효과를 검증하기 위해 SimCLR 에도 multi-crop augmentation을 적용합니다. 공정한 비교를 위해 2개의 일반적인 random crop augmentation을 수행할 때 SimCLR에서의 random crop ratio인 $s=(0.08,1)$을 사용합니다.
특히, SimCLR에 multi-crop augmentation을 적용하기 위해서는 한 배치안에 생기는 여러 positive pair를 고려해야 합니다. 배치 사이즈가 $B$이고 $M=V+2$라 할 때, $N=B\times M$의 crop을 생성하고 Equation 1의 목적 함수를 적용합니다. $v_i^{+}$의 경우 같은 데이터의 다른 augmentation이며 $v_i^{-}$는 배치 내 다른 데이터로부터 파생된 augmented 데이터입니다.

SimCLR에 multi-crop을 적용한 결과 SimCLR 또한 효과를 본 것을 확인할 수 있습니다. 특히 Figure 3의 오른쪽 그림을 보면 epoch를 증가시킬수록 성능이 지속적으로 증가하는 것을 볼 수 있습니다.

Unsupervised pretraining on a large uncurated dataset
MoCo에서와 마찬가지로 가공되지 않은 랜덤하게 추출된 10억개의 인스타그램 이미지를 통해 pretraining 한 후 ImageNet 데이터에 대해 실험합니다. 전체 레이어에 대해 fine-tuning 한 후의 성능은 스크래치로 훈련시킨 모델에 비해 성능이 더 좋습니다. 특히, MoCo의 경우 ImageNet 데이터와 연관있는 1500개의 해쉬태그로 추출한 이미지에 대해서 pretrain 시켰지만 SwAV는 가공되지 않은 인스타그램 이미지 그대로 사용했습니다. 또한 모델의 크기가 증가할수록 성능이 증가하는 것을 볼 수 있습니다.

'Machine Learning Tasks > Self-Supervised Learning' 카테고리의 다른 글
| Self-Supervised Learning - SwAV (1) (0) | 2021.04.17 |
|---|---|
| Self-Supervised Learning - MoCo v2 (0) | 2021.04.16 |
| Self-Supervised Learning - MoCo (2) (0) | 2021.04.16 |
| Self-Supervised Learning - MoCo (1) (0) | 2021.04.15 |
| Self-Supervised Learning - SimCLRv2 (2) (0) | 2021.04.09 |



